Introduction
_ _ _ _ | | | | | | (_) | |__| | _____ _____ ___| | ___ _ __ | __ |/ _ \ \/ / _ \/ __| |/ / | '_ \ | | | | __/> < (_) \__ \ <| | | | | |_| |_|\___/_/\_\___/|___/_|\_\_|_| |_| This column will contain helpful example queries and responses, along with additional information to help you understand how the REST API works. This documentation pertains to API version 3.3.x
This is the Hexoskin REST API reference Wiki.
The Hexoskin REST API allows you to interact and manipulate your Hexoskin data through HTTP requests. This includes accessing biometrics and user information, but also annotating data, viewing advanced reports, fetching metrics, and more.
Click here to access data resources doc directly.
Before getting started
Other ways to access your Hexoskin data
If you ended up here, you are probably interested in doing a bit more with your Hexoskin biometrics. However, if you just want to download your data, there might be an easier way than using the REST API. You can download your Heart Rate, Breathing Rate, Minute ventilation, Activity and cadence in CSV format, and the rest of the data in binary form directly from the dashboard. We provide scripts for Python and Matlab/Octave to help you convert them to .csv files, if you need. Have a look at this page and see if it’s sufficient for your needs.
Additionally, there is a Python client available, accessible on Bitbucket. If you have implemented the API in another language and want to share it, be sure to write us an e-mail at api@hexoskin.com and we’ll put it up along with the Python client.
Getting an API access
To use this REST API, you’ll need an API key or an OAuth access. The API supports both OAuth1 and Oauth2. If you don’t have an access already, email us at api@hexoskin.com with your project name and a quick description of what you want to do, and we’ll happily create you one. Make sure to create an account on our servers first - our access keys needs to be associated with an user.
So… What’s a REST API?
If you’re new to using APIs, you’re at the right place. You’ll need to understand the concept of REST API before you can do anything. Reading this will help, but you will probably have a little homework to do if you’re starting from scratch. If you already know what we are talking about, great! Jump ahead to the Hexoskin Getting Started section to get going.
For those still here, REST stands for REpresentational State Transfer and describes a way to make data accessible, generally via the Internet. A website like http://hexoskin.com is something you’re most likely already comfortable with. It’s a page that contains some information. To go to the developer section of the website, you can obviously click on a few button, but you can also add /pages/developers to the previous URL, and you’ll end up in the developer section. You just went from the general website to the developer-oriented page.
A REST API works in a very similar fashion. The entry point of the REST API is https://api.hexoskin.com/api/, and appending information at the end will bring you further down. For example, asking for https://api.hexoskin.com/api/account/ will return you your own account’s information. The information is returned as a JSON object, a standard format for such kind of information.
Something quite neat about REST APIs is that you can add arguments that will modify what the REST API returns to you. For example, take https://api.hexoskin.com/api/trainingroutine/. The response you receive will contain all training routines available to perform. But what if you want to look at the training routines that you have used? Well, looking at the trainingroutine documentation https://api.hexoskin.com/docs/resource/trainingroutine/, you see that there is a filter just for that. You can then query https://api.hexoskin.com/api/trainingroutine/?using=True, and voilà, you have used a filter to modify what the REST API returns to you.
One final thing to mention : While your web browser will allow you to fetch information from regular websites, our REST API requires additional information that the browser doesn’t provide. To interact with the REST API, you need to be using some programming language that allows you to specify some headers to the HTTP request you are making. That will allow you to GET, POST information, DELETE and PATCH some resources that you want modified.
Getting started
Overview and Technology
The API is built using Django and Tastypie. As such, the methods of querying the API follow the implementation patterns of Tastypie.
We have attempted to conform to RESTful practices as much as is practical. There are a few instances where a judicious departure has been indulged but overall you can assume things will work RESTfully.
API keys and OAuth requests
To perform (almost) any request, you need to authenticate either via API keys, basic auth or Oauth2. The API keys/Oauth2 tokens have their endpoint, located here https://api.hexoskin.com/api/accesstoken/ so you can view the keys associated with your account. When starting to perform requests, make sure your key’s status is either ‘oauth2’, ‘oauth1’ or ‘apikey’, depending on which one you want to use.
API Key identification
An example POST request with an API key would look something like this :
POST api.hexoskin.com/api/range/ From: mailer@mail.com User-Agent: HTTPTool/1.0 Content-Type: application/json Authorization: Basic ZmVtb2FjY291bnRaZGVtby5jb256ZGVtb3Bhc3N3c3Jp X-HEXOTIMESTAMP: 1234567890 X-HEXOAPIKEY: 3X4mP1ePu6licK3y X-HEXOAPISIGNATURE: 3x4mPl3ShA15igN4tUr33x4mPl3ShA15igN4tUr3
When performing a request, it has to be signed with your private API key, the timestamp, and the URL. Your API key has a public and a private portion. Never send the private key, only use it to sign the request. Send the public key. When looking at your key via the https://api.hexoskin.com/api/oauthclient/ endpoint, your public key is the ‘client_id’ and your private key is the ‘secret’.
To use the keys, you add three headers to each request:
Note : X-HEXOTIMESTAMP has to be a standard timestamp, it must be not be multiplied by 256 like the timestamp mentioned bellow
X-HEXOTIMESTAMP: a normal UTC timestamp.X-HEXOAPIKEY: your public key.X-HEXOAPISIGNATURE: the signature.
The signature is a SHA1 hash of the the private key, timestamp, and the URL (the entire URL, including the GET arguments). The order, of course, is very important. To help you remember, it’s alphabetic: Key, Timestamp, Url.
For example, if your private key is 3x4mPl3pR1v4tEK3y3x4mPl3pR1v4tEK3y, the timestamp is 1400000000 and the URL you want to query is https://api.hexoskin.com/api/user/, the pre-hash signature would be 3x4mPl3pR1v4tEK3y3x4mPl3pR1v4tEK3y1400000000https://api.hexoskin.com/api/user/, and the resulting hash would be 88c7a8e7b35f145ddac98f861476d89dc6604fb3.
OAuth General considerations
After getting your OAuth client keys, make sure to set the redirect url. To do that, you can send a PATCH on your client (located at https://api.hexoskin.com/api/oauthclient/[client id]/) on the “redirect_uris” field. The body of the request should look something like
{"redirect_uris": ["https://www.example.com/","https://www.hexoskin.com/"]}
During the OAuth token authorization process, only URLs already registered in the server will be accepted.
You can always view your list of tokens by looking at https://api.hexoskin.com/api/accesstoken/.
OAuth2 Authentication
OAuth 2 is the most streamlined version of both OAuth processes. you can find more details here: https://api.hexoskin.com/docs/page/oauth2/. The URLs used during the process are:
- For Authorization: https://api.hexoskin.com/oauth2/auth/
- For Token exchange: https://api.hexoskin.com/oauth2/token/
After receiving your authenticated token, you can query allowed resources by adding the “Authorization: Bearer [token]” header to your request.
API versions
A very important factor when developing is making sure you are querying the correct API version. The API has a default “current” version running which is the most up-to-date available. If you start developing, you might want to think about specifying an API version in your HTTP header. Failure to do so might break your code, if a resource you are using changes between two API versions.
To specify the API version, specify X-HexoAPIVersion: X.X.X, where X.X.X is the version you want to use.
HexoTimestamp
Timestamps are represented a little differently than is usual. Instead of representing the number of seconds since Jan 1, 1970 UTC (UNIX timestamps), they represent the number of 256ths of a second since Jan 1, 1970 12:00:00pm UTC. In other words, they are a regular epoch timestamp multiplied by 256. All timestamps in the system are like this unless explicity noted. This modification allows the ECG’s timestamps to be stored as integers, since it has the highest sampling rate, at 256Hz.
Note: The HexoTimestamp is only for the request parameters, it is not used for the `X-HEXOTIMESTAMP` authentication header
Making Requests
All requests are conducted over SSL. Any non-SSL requests received are forwarded to HTTPS.
Currently, only JSON is supported for non-data resources. For data resources, JSON, CSV and octet-stream are supported, though JSON and CSV have limitations (see data). Set your headers accordingly.
On the whole, interactions with the API behave as described in Tastypie’s documentation. A couple of notable restrictions are:
DELETE and PUT requests to list views are always denied. PUT to a detail view of a non-existant instance will not attempt to create the instance, it will result in a 404. POST requests to detail views are always denied.
Retrieving Resources
List views
A typical list view, for example taken from https://api.hexoskin.com/api/datatype/ looks like:
{
"meta": {
"limit": 20,
"next": "/api/datatype/?limit=20&offset=20",
"offset": 0,
"previous": null,
"total_count": 95
},
"objects": [
{
"dataid": 208,
"hexo_freq": null,
"info": "Recorder start annotation.",
"name": "RECSTR_ANNOT_CHAR",
"resource_uri": "/api/datatype/208/"
},
{
"dataid": 16,
"hexo_freq": 1,
"info": "1 to 3 leads ECG channel(s).",
"name": "ECG_CHANNEL_CHAR",
"resource_uri": "/api/datatype/16/"
},
{
"dataid":"..."
}
]
}
To get a list of resources, you make a GET request to the resource’s endpoint. For instance, to retrieve datatypes you would access the following resource:
https://api.hexoskin.com/api/datatype/
Resources are represented as URIs. URIs generally conform to the following model:
/api/[resource name]/
For example, all the datatypes are found by issuing a GET request to:
/api/[resource name]/[ID]/
This is a “list view” because it will return a list of all the instances of that resource that the current user is allowed to see.
Note that the resource name is singular and there is a trailing slash. Also note that by default, a list’s limit of returned objects is 20. To change that, you have to specify the ?limit= argument in your GET query. The response will never return more than 1000 objects, except for data resources, where that limit is 65535.
Requests to lists return an object containing two members; meta contains information about the results and objects contains the actual results. A sample result from /api/datatype/?offset=20 is shown on the right panel.
As you can see, the meta object tells us how to page through the data. You can roll your own paging routines of course, but you may also use the next and previous attributes of the meta object. The limit and offset variables are passed in the GET to determine which page to retrieve.
Filtering and Ordering
An example query containing a filter: https://api.hexoskin.com/api/record/?device__in=HXSKIN1200001773,HXSKIN1200002049
{
"meta": {
"limit": 20,
"next": null,
"offset": 0,
"previous": null,
"total_count": 13
},
"objects": [
{
"data": "TfzfJ1QAAABIWERFVi1BVVRPTXwAAAAAhQoAAEZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGAQAFAA==",
"data_status": {},
"dev_id": "FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF",
"device": "/api/device/HXSKIN1200002115/",
"end": 361451358544,
"firmware_rev": "1.0.5",
"id": 43419,
"n_uploaded_timelines": 0,
"npages": 71710,
"resource_uri": "/api/record/43419/",
"soft_protocole": 0,
"soft_uid": "HXDEV-AUTO",
"start": 361446243405,
"start_date": "2014-09-28T10:16:28+00:00",
"status": "complete",
"user": {
"email": "athlete@hexoskin.com",
"first_name": "Athlete",
"id": 1511,
"last_name": "Hexoskin",
"profile": "/api/profile/1460/",
"resource_uri": "/api/user/1511/",
"username": "athlete@hexoskin.com"
}
},
{
"data":"..."
}
]
}
Variables for filtering and ordering the results are also passed through the GET arguments. You can filter on any combination of fields and filter types in the Filtering Options of a resource. Refer to the ‘Filtering Options’ section of endpoint’s documentation to determine what these are for that resource. For example, the record resource supports the following filtering options:
- device: exact, in
- start: exact, range, gt, gte, lt, lte
- end: exact, range, gt, gte, lt, lte
- user: exact, in
You use a filter type by passing a GET argument of [column]__[filtertype]=[value]. So to view a list of records that contains only records that started on or after a start timestamp of 347631277170, you would append start__gte=347631277170 to the URL like this:
https://api.hexoskin.com/api/record/?start__gte=347631277170
If no filtertype is specified, exact is assumed. so user__exact=/api/user/99/ is the same as user=/api/user/99/. For simplicity, user=9 will also work.
Ordering works in a similar fashion. Columns which support ordering are listed in each endpoints' documentation under ‘Sorting Options’. You may pass order_by= followed by a comma-separated list of columns. The sort order is ascending by default, to make the sort order descending prepend the column name with a -. So to add a descending order to our record query, you would make the following request:
https://api.hexoskin.com/api/record/?start__gte=347631277170&order_by=-start
Detail views
A typical detail view, this one taken from https://api.hexoskin.com/api/datatype/208/, looks like :
{ "dataid": 208, "freq": null, "info": "Recorder start annotation.", "name": "RECSTR_ANNOT_CHAR", "resource_uri": "/api/datatype/208/" }
You may query a specific instance of a resource by accessing its URI. You are strongly encouraged to use the resource_uri attribute that is provided with each resource, however if you prefer to create them, they generally follow the pattern of the list URI with the ID appended:
/api/[resource name]/[ID]/
So to access the Recorder start annotation datatype directly, you would make a GET request to:
https://api.hexoskin.com/api/datatype/208/
Note that the detail view does not contain a meta and object attribute, the resource instance is returned directly.
Create, Update and Delete
For example, a POST on annotation with the following content:
{‘datatype’: ‘4096’, ‘start’: 123456, ‘user’: 835, ‘annotation’: ‘Hey guys!’}
will return the following content:
{
"annotation": "Hey guys!",
"datatype": "/api/datatype/4096/",
"id": 61353,
"last_update": 362161472635,
"record": null,
"resource_uri": "/api/annotation/61353/",
"start": 123456,
"start_date": "1970-01-01T00:08:02+00:00",
"user": "/api/user/835/"
}
Creating an instance of a resource is achieved by issuing a POST or a PATCH request to the list view of the desired resource. If the instance is created is successfully, you will receive a 201 with the location of the new resource in the Location header. For many resources, the instance will be in the body but sometimes, primarily in cases where there is a lot of data involved, the instance representation is omitted.
Not all resources support PATCH requests and some don’t support creation at all! Please refer to the documentation for each resource to see what methods are supported and which fields must be supplied.
To update an instance, you may send a PUT or a PATCH to the URI of the resource instance you wish to update. As with creation, support for different methods vary between resources, be sure to check the documentation.
If you use the PATCH method, it is not necessary to supply the entire object, you may supply only the fields you wish to change. If you use the PUT method you must provide a complete object to replace the existing one.
Deleting, as one would expect, is done by sending a DELETE request to the resource instance’s URI.
Cached Content
The API caches results to improve performance. If your are receiving a cached response, the X-HexoCache header will be present in the response and will contain a timestamp (normal timestamp, not a HexoTimestamp) of the time it was cached.
Error Codes
400 Bad Request
There is a problem with the data or the format of the data supplied.
401 Unauthorized
Your authentication failed.
403 Forbidden
Your user is not allowed to do what your are trying to do.
404 Not Found
The resource does not exist or you are not allowed to see the resource instance requested.
405 Method Not Allowed
You have attempted to use a method which is not allowed on the given resource.
500 Server Error
The API has encountered an error.
Operations Examples
This section contains example operations, displaying some functionalities of the REST API. However, before jumping in, there will be a quick overview of the Hexoskin ecosystem (some resources and their interactions). Read away if this is interesting to you, or jump straight to the examples.
Hexoskin ecosystem overview
At this point, you might have some data collected or are looking at the demo account, and are wondering: What are the different building blocks of this API and how do they interact together? Is there anything important that I should know before getting into this? Before getting in the detailed filters and query descriptions, this section will give you a quick overview of the Hexoskin ecosystem.
For starters, to find all hexoskin-collected data you have to specify a timestamp range and a user. When a user connects his hexoskin to the shirt, a Record is created. A Record consists, among others, of a user, and a start and end timestamp. Because of that, when asking for data, you can either query directly by timestamp, or instead ask for a record’s data directly. Since records are always created over Hexoskin-collected data, you should never find any data outside of a record. Since it comes from the mobile phone directly, all GPS data is instead aggregated in the Ranges. Speaking of which, Ranges, often referred to as activities, are a way for you to annotate what you were doing at a given time. Ranges have, among other attributes, a name, a start and end time, and an user. When using the mobile application, setting the activity will start the GPS data collection if applicable, and that data will be available for that Range.
All Hexoskin-collected data is separated in datatypes. Each datatype has it’s own ID, and when accessing data, you pass a list of datatype IDs in the request.
Some Ranges will trigger additional processing, making more data available to you. Depending on the activitytype of the trainingroutine of the range applied, HRV, sleep positions, and more become available. Refer to the activitytype documentation to see what makes which data available. The relationship between ranges, trainingroutines and activitytypes is very simple : An activitytype is a broad category that regroups multiple trainingroutine together and that tells us if some special processing must be done. For example, Resting is an example of activitytype and tells us to process HRV. trainingroutine are just a specific type of activity. The trainingroutine indicates if the GPS should be started when using the application via the ‘geo’ field in metadata, but otherwise, it’s just a slightly more specific categorization of the range. ranges are the instance of a trainingroutine. When performing an activity and annotating it on the phone, a range is created, allowing the user to easily find back “that time” he did “that thing”.
In the API, there is a coach-athlete and friend relationship. They differ by the kind of permissions they provide to the affected users. As someone’s friend or as his coach, his data will appear in the responses, unless you filter them out. Athletes do not see the coach’s data.
Getting user profiles
https://api.hexoskin.com/api/account/
{
"meta": {
"limit": 1,
"next": null,
"offset": 0,
"previous": null,
"total_count": 1
},
"objects": [
{
"email": "athlete@hexoskin.com",
"first_name": "Athlete",
"id": 1511,
"is_staff": false,
"last_name": "Hexoskin",
"profile": {
"date_of_birth": "1980-01-01",
"fitness": {
"fitness_percentile": 50,
"height": 1.82,
"hr_max": 183,
"hr_recov": 0,
"hr_rest": 73,
"vo2_max": 42,
"weight": 78
},
"gender": "M",
"height": 1.82,
"id": 1460,
"preferences": null,
"resource_uri": "/api/profile/1460/",
"unit_system": "metric",
"weight": 78
},
"resource_uri": "/api/user/1511/",
"username": "athlete@hexoskin.com"
}
]
}
There are two ways of accessing user information. Using
https://api.hexoskin.com/api/account/
will always return you only the authenticated user’s data. However, if you have friends or athletes under your account, you can see their account information with
https://api.hexoskin.com/api/user/
The list you receive contains summaries of all users you can see’s informations. This includes the authenticated account, and any friend or athlete that user has. In this summary view, the profile is returned as an URI. To access a specific user’s profile, either ask for
https://api.hexoskin.com/api/profile/[ID]
or get the detail view of the user’s data with
https://api.hexoskin.com/api/user/[userID]
Be sure to not mix up the user’s ID with his profile’s ID, as they will most likely differ.
Getting biometric data - JSON
https://api.hexoskin.com/api/data/?datatype__in=19,33&record=37700
[
{
"data": {
"19": [
[
359840227126,
70
],
[
359840227382,
71
],
["..."]
],
"33": [
[
359840227126,
12
],
[
359840227382,
13
],
["..."]
]
},
"user": "/api/user/1511/"
}
]
Because Hexoskin records lots of data, all hexoskin-recorded data is neatly organized in separate datatypes that you can query individually. You can view a list of all existing datatypes by using :
https://api.hexoskin.com/api/datatype/
Because it is returning a list view, the previous call returns a maximum of 20 objects. If you want to see a different subset, check out List views for more information.
When you know which datatypes you need, you need to decide for which time frame you want them. To do so, you can pass a range or record. To get a list of records, for example, you can call :
https://api.hexoskin.com/api/record/
Now that you know what data you want, and for which record, you can query as follow, using the IDs of the resources you want :
https://api.hexoskin.com/api/data/?datatype__in=19,33&record=37700
The previous query will return the datatype IDs 19 and 33 (heart rate and breathing rate) for record 37700.
Note that when asking for JSON, all data is limited to return a maximum of 65535 points. If the time range you are asking for would contain more points (such as 257 seconds or more of 256Hz EKG, for example), the data returned is subsampled appropriately to return the max number of data points. If you don’t want to have to parse through data or want to receive everything not subsampled, use the Binary format (described next) instead.
Getting biometric data - Binary
The following Python script converts your binary files data and prints it.
# Decode WAV file import struct data = struct.Struct("h") #Binary format : short with file('record_37700/ECG_I.wav', 'r') as f: f.seek(44) # Skip WAV headers bytes = f.read(data.size) while bytes: print data.unpack(bytes) bytes = f.read(data.size) """ Output for synchronous data: (1352,) (1236,) (1193,) ... """ #Decode asynchronous file (.hxd) import struct data = struct.Struct("Qq") # Binary format : Unsigned long long, long long with file('record_37700/RR_interval.hxd', 'r') as f: bytes = f.read(data.size) while bytes: print data.unpack(bytes) bytes = f.read(data.size) """ Output for asynchronous data: (85, 256) (154, 69) (234, 80) ... """
If you are interested in the full, unsubsampled raw data, you might want to consider getting it using the Accept: application/octet-stream header. This will return your data in compressed zip binary format. So for example, you wanted to download the raw ECG and RR interval for a given record, you would first call
https://api.hexoskin.com/api/data/?datatype__in=4113,18&record=37700
with the header Accept : application/octet-stream, which will write the output to a Zip file.
The previous call sets the Accept header to application/octet-stream to download the data in the binary format, then outputs the data to the record_37700 zip file. Datatype 4113 stands for ECG, and 18 for RR interval.
The next step is to unzip the compressed file. You can call
unzip record_37700.zip
which will create the record_37700 directory, containing ECG_I.wav and RR_interval.hxd, our binary files.
In this case, the ECG is synchronous, while the RR interval data is asynchronous.You can use the example on the right to guide you and find the equivalent to decode both files in your favorite programming language.
As mentionned in the data resource documentation:
“Syncronous data is returned as a RIFF/WAV file and asynchronous data is returned as a series of timestamp/value pairs encoded as long longs (8 bytes).” This means that synchronous data does not contain the timestamps. You can easily know when a sample has been acquired though, because you can access the record start and know the sampling rate. For the asynchronous data, the first column represents the offset from the record’s start, in HexoTimestamp.
Getting GPS data
https://api.hexoskin.com/api/track/
{
"meta": {
"limit": 20,
"next": "/api/track/?limit=20&offset=20",
"offset": 0,
"previous": null,
"total_count": 10
},
"objects": [
{
"area": null,
"distance": 656.763124754487,
"id": 80,
"name": "",
"range": "/api/range/58979/",
"resource_uri": "/api/track/80/",
"source": "",
"user": "/api/user/805/"
},
{
"area":"..."
}
]
}
https://api.hexoskin.com/api/trackpoint/?track=80
{
"meta": {
"limit": 20,
"next": "/api/trackpoint/?track=80&limit=20&offset=20",
"offset": 0,
"previous": null,
"total_count": 53
},
"objects": [
{
"altitude": 42,
"course": null,
"horizontal_accuracy": 3.90000009536743,
"id": 27720,
"position": [
-73.6045937,
45.5308797
],
"resource_uri": "/api/trackpoint/27720/",
"speed": 0,
"time": "2014-08-29T09:25:15",
"track": "/api/track/80/",
"vertical_accuracy": null
},
{
"altitude": "..."
}
]
}
GPS data, collected by the mobile phone, is stored in the trackpoint endpoint. Whenever a range acquires GPS data, it creates a track object. You can list all available tracks using
https://api.hexoskin.com/api/track/
Tracks contain a reference to the range that is associated with it. Once you know which range, and thus which track you want, just query
https://api.hexoskin.com/api/trackpoint/?track=80
The trackpoint resource contains all GPS points related to the given track.
Additionnally, GPS data can be accessed via timestamps or time filters. The following two queries yields the same results :
https://api.hexoskin.com/api/trackpoint/?user=36×tamp__range=366452901376,366453822976
and
https://api.hexoskin.com/api/trackpoint/?user=36&time__range=2015-05-12T18:50:46,2015-05-12T19:50:46
Getting Metrics
https://api.hexoskin.com/api/report/?include_metrics=1,44&record=37700
{
{
"metrics": [
{
"name": "activity_avg",
"outputtype": "value",
"resource_uri": "/api/metric/1/",
"title": "Act Avg",
"unit": {
"id": 450,
"info": "",
"resource_uri": "/api/unit/450/",
"si_long": "g,acceleration",
"si_short": "g"
},
"value": 0.158528803165781,
"zone": 2,
"zones": [
0,
0.1,
0.2,
0.3,
0.4,
0.5
]
},
{
"name": "heartrate_avg",
"outputtype": "value",
"resource_uri": "/api/metric/44/",
"title": "HR Avg",
"unit": {
"id": 700,
"info": "",
"resource_uri": "/api/unit/700/",
"si_long": "beats per minute",
"si_short": "bpm"
},
"value": 103.285529715762,
"zone": 6,
"zones": [
65,
67,
70,
72,
74,
88
]
}
],
"timeranges": [
{
"end": 359840821814,
"start": 359840226870,
"user": "/api/user/1511/"
}
]
}
Along with the actual data from the hexoskin, metrics are also available. Metrics are a way to summarize data in a single values or histograms. A few example of metrics are heart rate average, max activity, minimum breathing rate and so on. A few noteworthy metrics are :
- Average, min, max:
- Activity: 1,3,4
- Breathing rate: 12,14,15
- Cadence : 17,19,20
- Heart rate: 44,46,47
- Minute ventilation: 55,57,58
- Step count: 71
- Sleep total time, Sleep position changes, Sleep efficiency : 1032,1038,1039
- Total energy consumed (kCal): 126
You access the full list of metrics using a similar pattern than for datatypes :
https://api.hexoskin.com/api/metric/?limit=1000
When you have your own list of favorite metrics, you can query the following (replacing “1,44” by your very own list)
https://api.hexoskin.com/api/report/?include_metrics=1,44&record=37700
and the metric data will be appended to the record’s information.
Analyzing HRV
https://api.hexoskin.com/api/report/?include_metrics=173&range=63624
{
"metrics": [
{
"name": "HRVLFnorm_avg",
"outputtype": "value",
"resource_uri": "/api/metric/173/",
"title": "HRVLFnorm avg",
"unit": {
"id": 3,
"info": "",
"resource_uri": "/api/unit/3/",
"si_long": "percent",
"si_short": "%"
},
"value": 69.8,
"zone": 2,
"zones": [
50,
60,
70,
80,
90,
100
]
}
],
"timeranges": [
{
"end": 361674727680,
"start": 361674650880,
"user": "/api/user/36/"
}
]
}
First off, you have to know HRV is only computed for select ranges, in select conditions. This is because HRV is a very picky measure, requiring very high quality data, and a large RR intervals sample. As such, a range will have HRV metrics available only if :
- It contains more than 128 correctly detected heartbeats. Try not to take the smallest possible sample, go with volume, the quality of calculation increases as the sample size grows.
- The ECG data signal-to-noise ratio is high (little noise in the signal).
- The activitytype id of the trainingroutine assigned to the range is either 106, for Rest Test, or 12, for Sleep. That means the range has to have a training routine of either id 12 (Sleep) or 1016 (5 minute Rest test).
- The whole record has been synchronized with HxServices. HRV will NOT be computed in real-time.
Once a range meets those criterions, the HRV will be calculated on the server and be available to access. Using the Getting metrics method above, try accessing metric id 50, which is the HRV average. A returned value of -1 means that the HRV has not been calculated correctly.
In addition to metric ID 173, there are a few channels that are related to the HRV that can be accessed. They are described in the HRV section.
Import/Export
TCX and FIT exchange formats
An important aspect of any fitness platform is interoperability. As such, the API supports TCX and FIT format import and export. Both Range and Training Routine export/import are supported.
Export
When querying a Range or a Record via /api/record/[id]/ or /api/range/[id]/ on the API, you can specify the following headers. Instead of returning a JSON response, the server will return either a TCX or FIT file that contains your data. It is also possible to query /api/trainingroutine/[id]/ to get a TCX or FIT representation of a given training routine.
Accept:application/vnd.garmin.tcx+xmlfor TCX exportAccept:application/vnd.ant.fitfor FIT export
You can refer to these format’s standards for more details regarding the format. Note that for TCX format, the output will contain data for every second (heart rate, breating rate, tidal volume, minute ventilation and energy in Watts), and GPS points only where available. For FIT files, there will only be data at moments where GPS position has been reported, leading to a much smaller file size.
Import
In addition to being able to export the TCX/FIT files, the API supports import of those formats. Using the following headers :
Content-Type:application/vnd.garmin.tcx+xmlfor TCX exportContent-Type:application/vnd.ant.fitfor FIT export
you can post your activity or training routine to https://api.hexoskin.com/api/import/. You can directly send the content in the raw body of the POST request, or send it as a binary. The response will contain a resource_uri field that you can then query to follow the uploading progress of you file. This will be located in something like https://api.hexoskin.com/api/import/[upload id]/
When importing a Range this way, the system will always create a range. If the file contains biometric data (Heart rate, breathing rate, etc…), a record will also be created and will be in the response. Laps will be created as ranges too, but their rank will be 1 (the top-level range’s rank is always 0).
Data Export formats
When querying the /api/data/ endpoint, the default response format will be JSON. However, you can specify the following headers in your query to receive the data in the specified formats:
Accept: application/jsonfor jsonAccept: text/csvfor csv (only exports 1Hz data)Accept: application/octet-streamfor binaryAccept: application/x-edffor edf
Resources
The full, latest list of available (auto-generated) resources is located at https://api.hexoskin.com/docs/resource/. In case anything seems off in the documentation below, refer to that page.
The full list of available datatypes is available through /api/datatype/?limit=0
Biometric Resources
https://api.hexoskin.com/api/data/?datatype=4113&record=43419
[
{
"data": {
"4113": [
[
361446243405,
1715
],
[
361446243484,
1423
],
[
...
]
]
},
"user": "/api/user/1511/"
}
]
This section describes the various biometric resources. All datatypes are available either through the URLs described in each respective section, or alternatively through the /api/data/ endpoint described just below. Using the ?datatype__in= filter will allow you to request more than one datatype easily.
The following sections will link to the most up-to-date documentation for each resource. The broad category for each resource will briefly describe the relationship between the various resources under it.
Data
Doc: https://api.hexoskin.com/docs/resource/data/
The data endpoint is the easiest way to access biometric data, as it allows you to make a single query to fetch multiple different datatypes, provided you know the datatype’s IDs. An example query using data would be:
https://api.hexoskin.com/api/data/?datatype=19,33,34&record=37700
which would return datatypes 19, 33 and 34.
You can check out the data export format section for additionnal export formats beyond JSON.
Datatype
Doc: https://api.hexoskin.com/docs/resource/datatype/
The datatype resource allows you to view a list of available datatypes.
The most common datatypes IDs are as follows:
1Hz Data:
- Heart rate: 19
- Breathing rate: 33
- Minute ventialtion: 36
- Activity: 49
Raw data:
- ECG: 4113
- Thoracic respiration: 4129
- Abdominal respiration: 4130
- Acceleration X: 4145
- Acceleration Y: 4146
- Acceleration Z: 4147
Asynchronous:
- Steps: 52
- RR interval: 18
- Inspirations detections: 34
- Expirations detections: 35
Heart rate related
ECG is the key for all resources here. From the ECG, we detect the QRS complex (the peak that represents a heartbeat). The time interval between these QRS complexes is available through the RR interval resource. The RR interval is used to compute the Heart rate.
The Heart rate status shows various flags related to signal quality to help you detect if the data is reliable or not.
ECG Raw Data
https://api.hexoskin.com/api/data/?record=43419&datatype=4113,
[
{
"data": {
"4113": [
[
361446243405,
1715
],
[
361446243484,
1423
],
[
...
]
]
},
"user": "/api/user/1511/"
}
]
Doc: https://api.hexoskin.com/docs/resource/datatype/#ecg
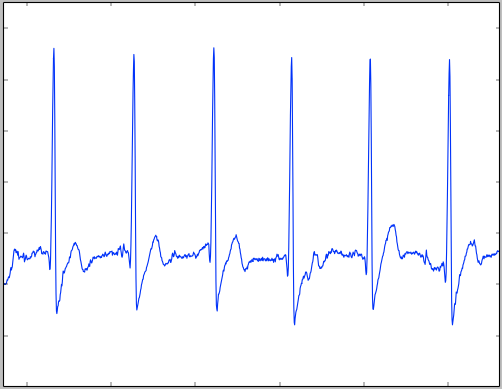
Heart rate
Doc: https://api.hexoskin.com/docs/resource/datatype/#heart_rate
Heart Rate Status
Doc: https://api.hexoskin.com/docs/resource/datatype/#heart_rate_quality
https://api.hexoskin.com/api/data/?record=37700&datatype=1000
[
{
"data": {
"1000": [
[
359840227126,
32
],
[
359840227382,
32
],
[
359840227638,
40
],
[
359840227894,
32
]
]
}
}
]
In that example, the 32 value translates to : 0010 0000, which means only the 6th flag is up. The RR interval is unreliable at that point.
Next, a value of 40 is given. The bit representation is 0010 1000. That means the RR interval is unreliable and that the signal is saturating.
Later on (not shown in this excerpt of the data), the value falls to 0, which means that the data is in top condition and ready for interpretation.
Heart rate status is a bit of a special channel : it contains information on the perceived quality of the data. The value is returned as an Integer, but the bits is what needs to be interpreted, as each bit represents a potential flag, explained below. The Hexoskin uses those flags to know if the QRS detected are reliable or if they should be ignored. As such, there might be discrepancies between detected QRSes and the returned heart rate if some of the flags below have been set.
- 1st bit : Currently unused, always 0.
- 2nd bit : DISCONNECTED : Does it seem like there is no shirt connected or that no one is in it?
- 3rd bit : 50_60HZ : Is there presence of a significant amount of 50 or 60Hz noise in the signal?
- 4th bit : SATURATED : Does the signal intensity go beyond the dynamic range?
- 5th bit : ARTIFACTS : Is any movement artifact detected?
- 6th bit : UNRELIABLE_RR : Does the rr interval seems supiciously unreliable? Happens either when the signal quality is low and qrs are not detected correctly, or when tachycardias or brachycardias are present.
If you need, an example of how to interpret the data is given in the right-panel example.
Below are examples of what the ECG looks like when each kind of flags are up:
DISCONNECTED
Disconnections looks like the following. Note the scale, the variations are extremely small.
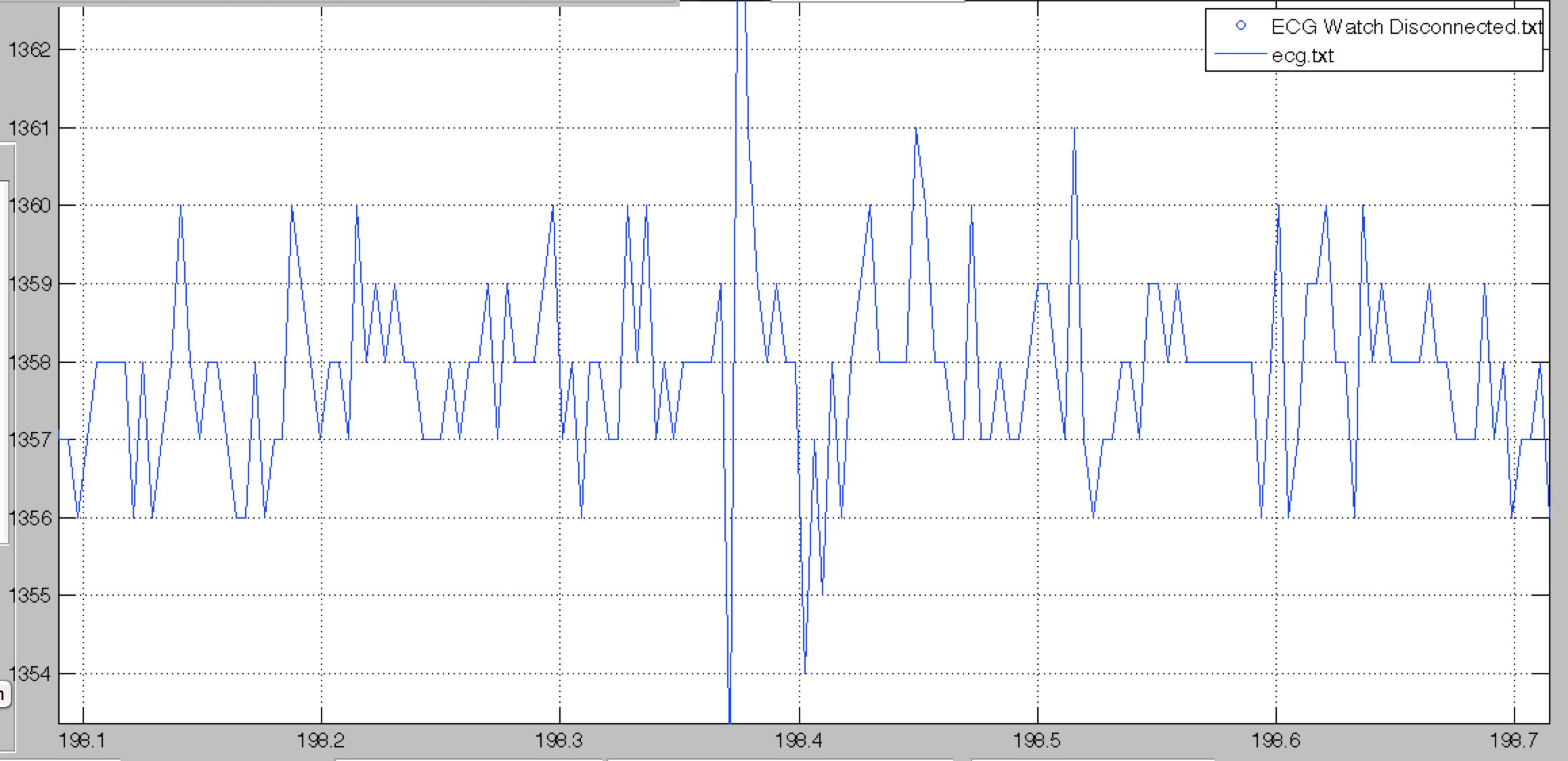
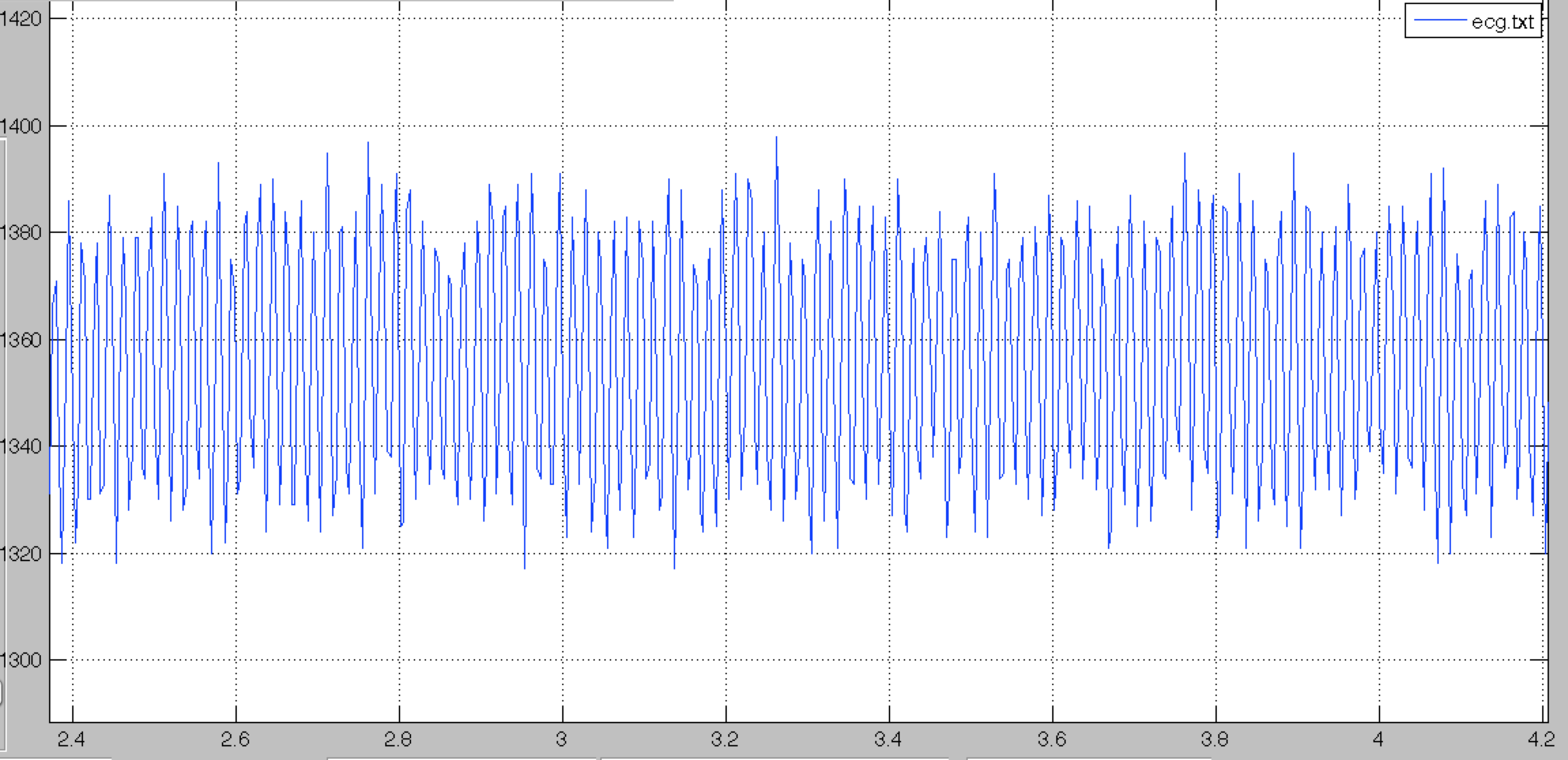
50_60Hz
Manageable 50-60Hz component looks like the following. Our QRS-detections algorithms can filter out this component and the QRS should be detected correctly.
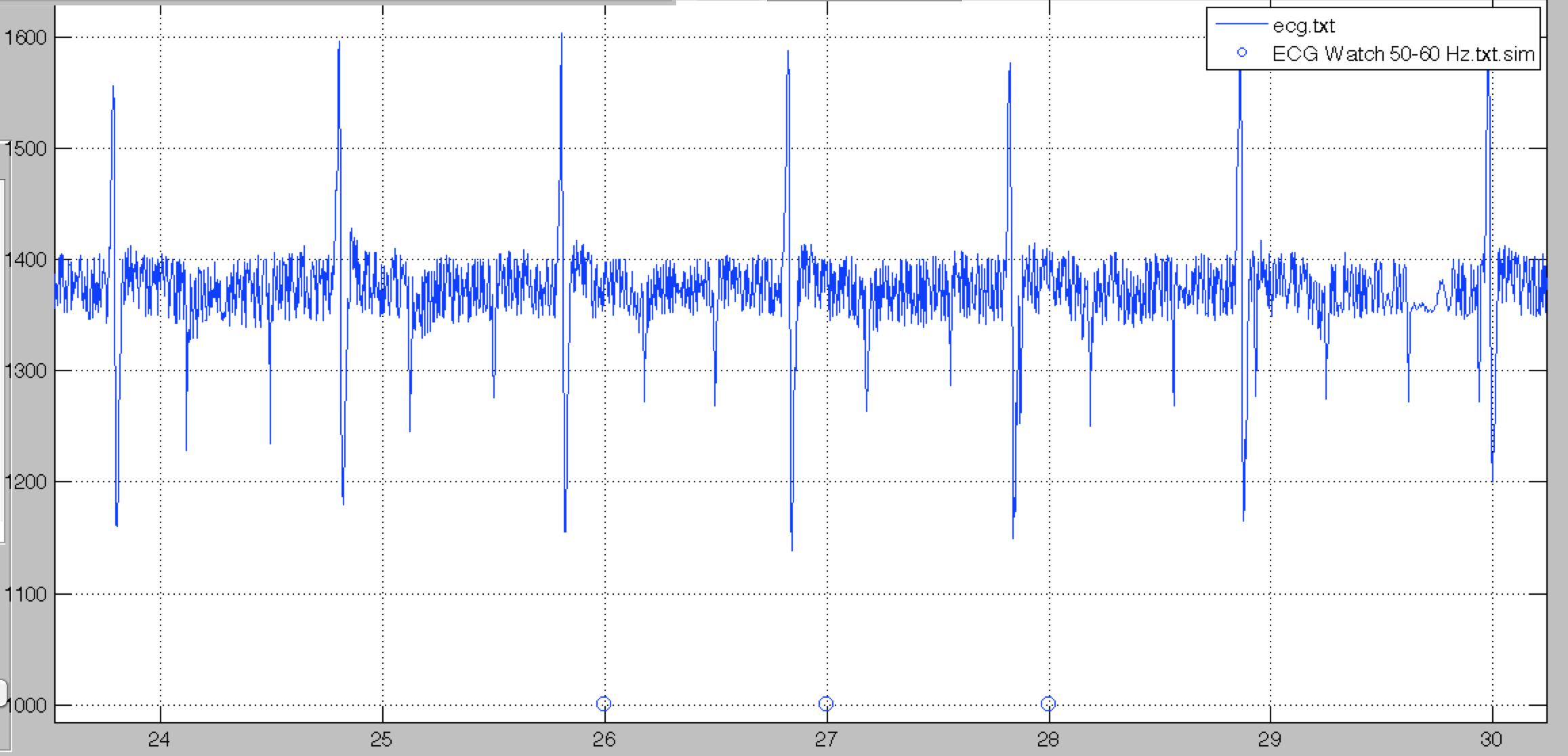
However, in the following case, the 50-60Hz component is too important, even heavy filtering can not get rid of the noise.
SATURATED
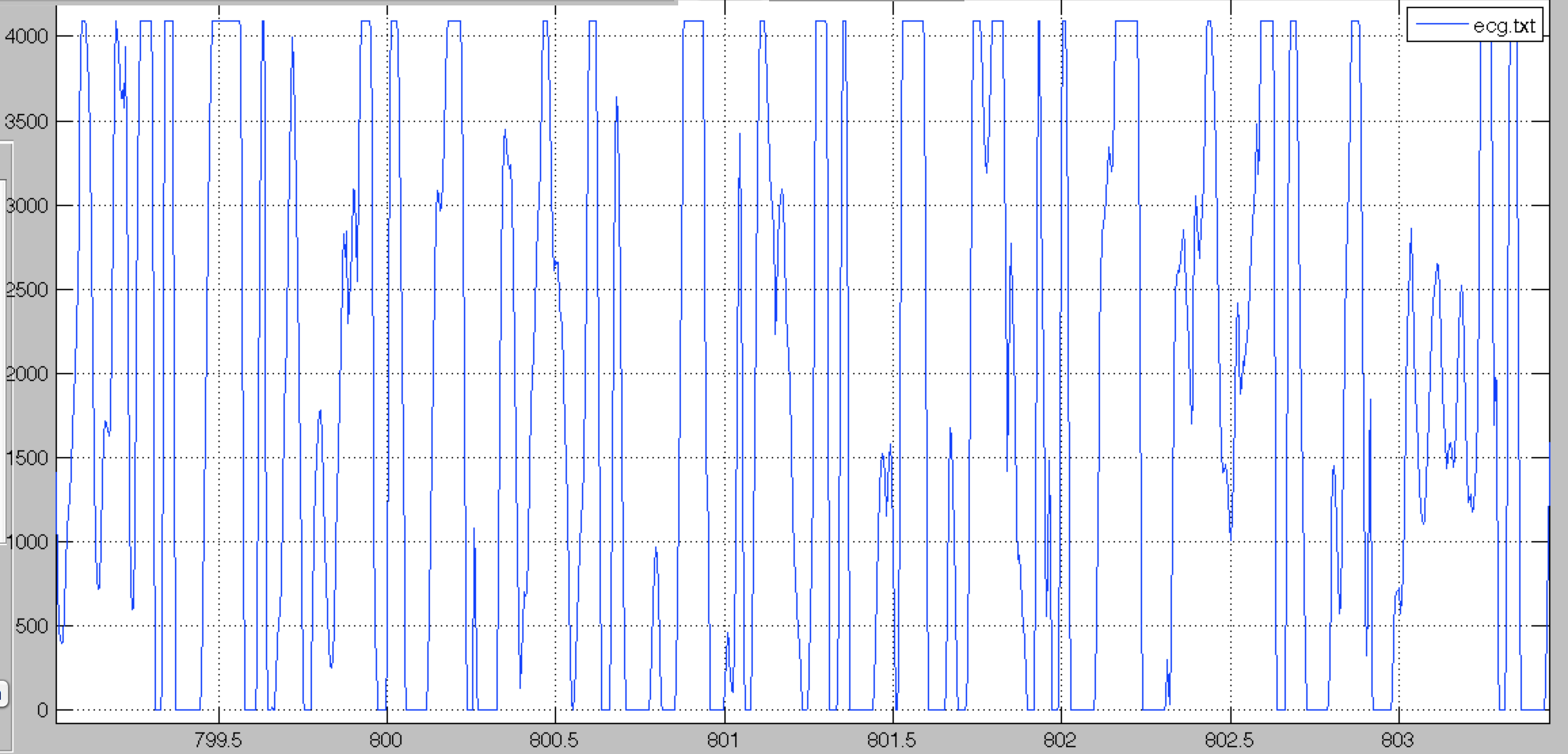
Spontaneous saturation looks like the following. It can happen if one or more of the shirt’s electrodes stop making contact with the skin for a few moments. The next QRS might be missed, but the QRS detection algorithm should recover quickly.
In the following case however, the saturation is too important for the algorithm to detect anything reliably.
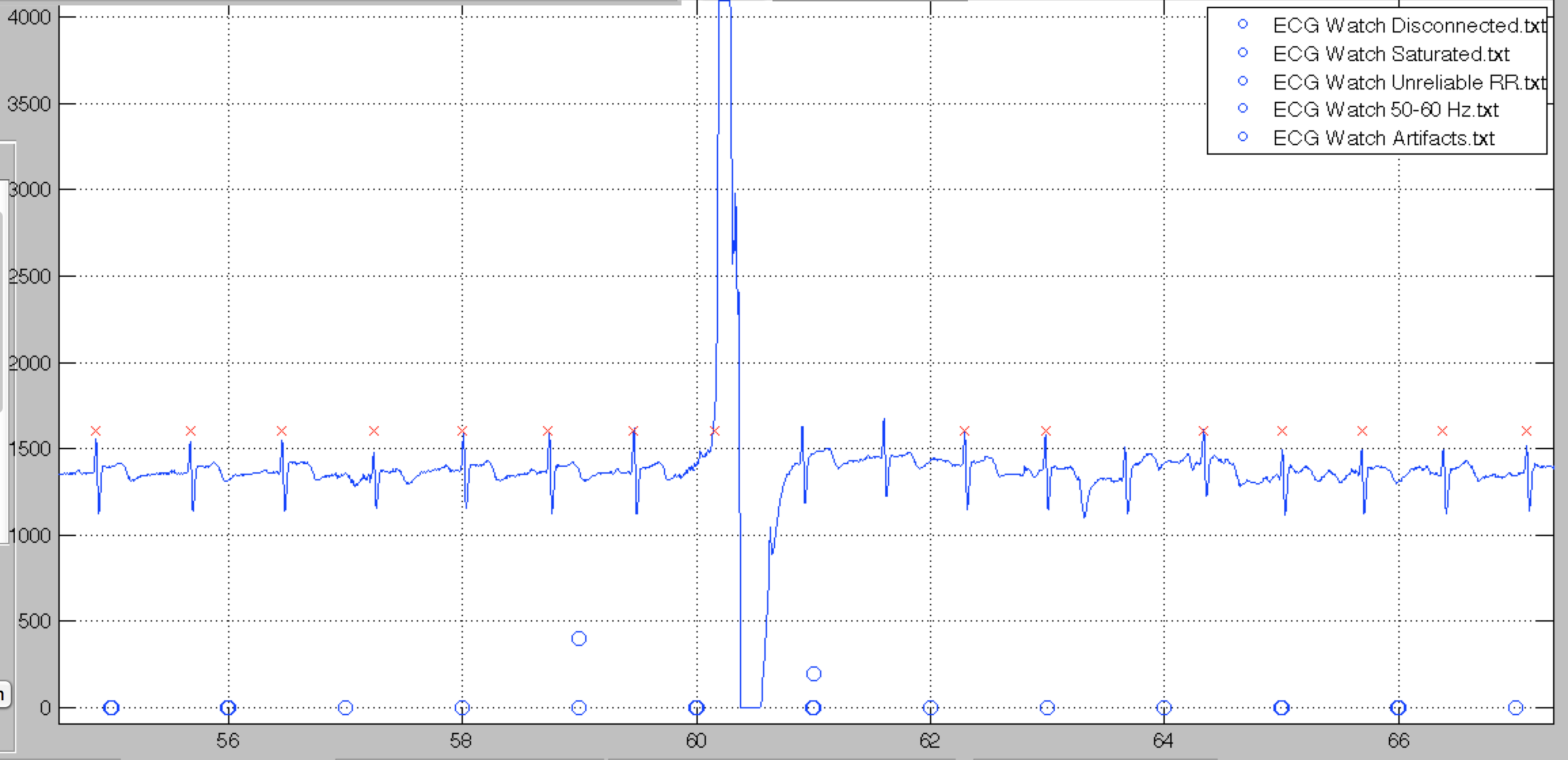
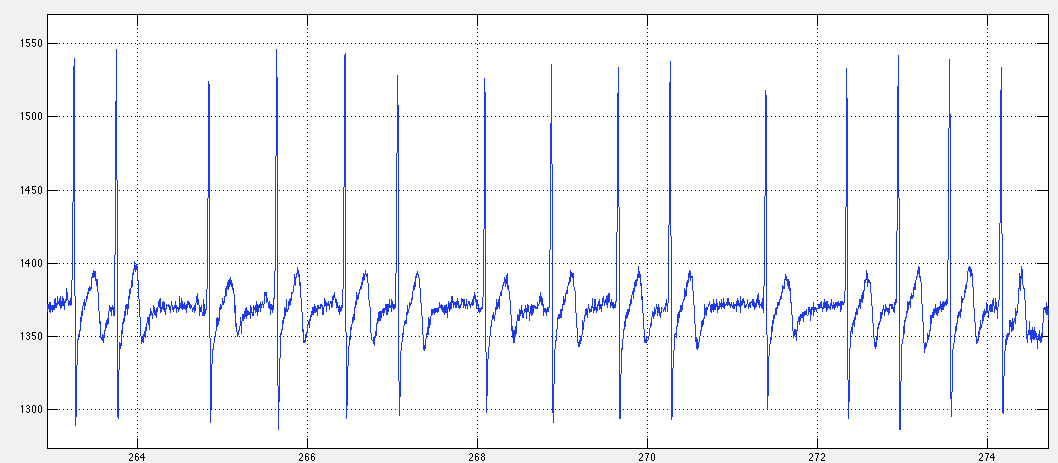
ARTIFACTS
Movement artifacts looks like the following. Red X'es represents QRS detections - As you see sometimes this kind of noise can be interpreted as a QRS, although it will not always be the case, depending on the spectral components of the noise. QRSes detected while the movement artifact flag is up should be interpreted with caution.
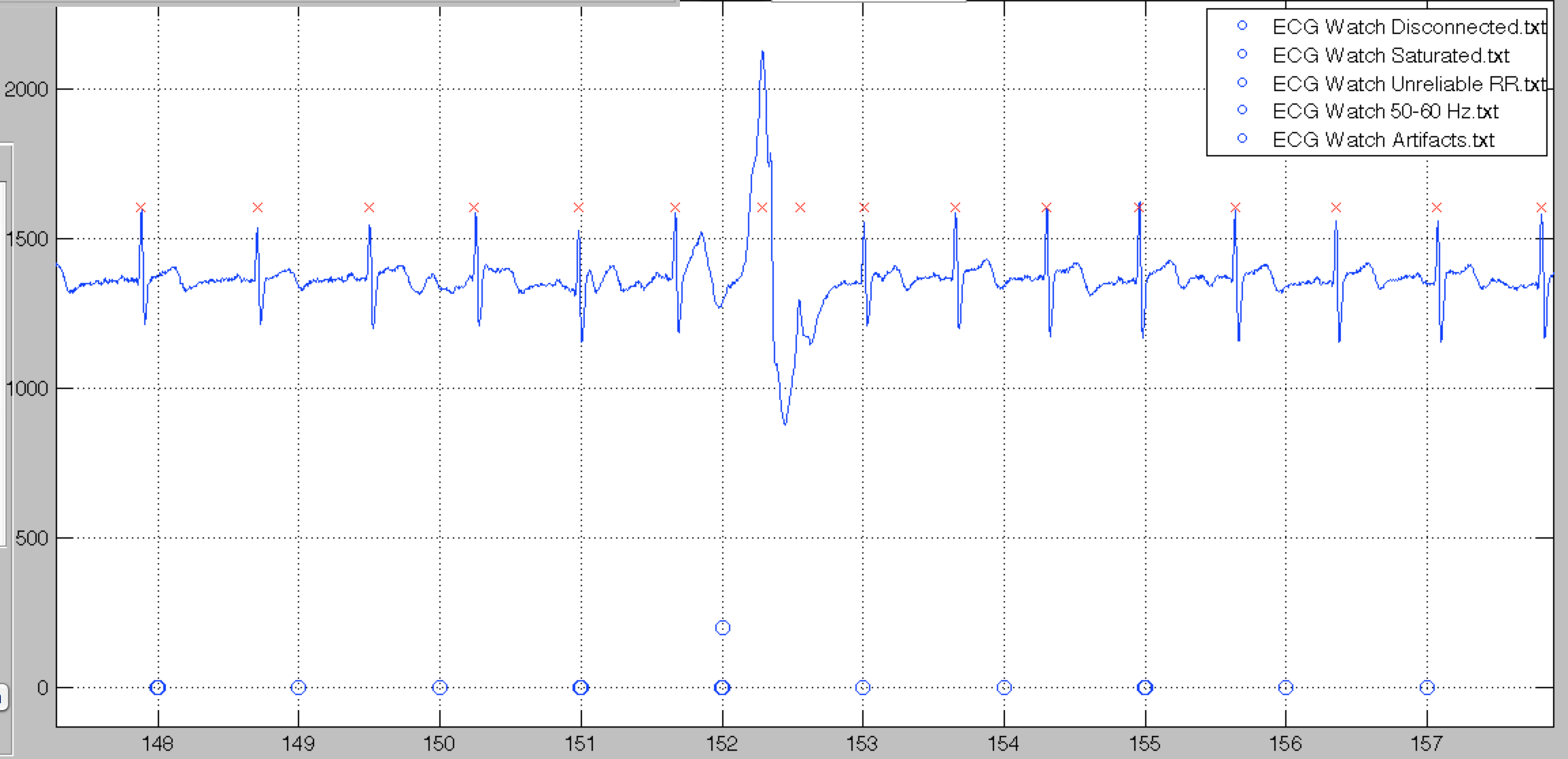
UNRELIABLE_RR
Finally, our algorithm expect a certain regularity of the QRS intervals. If a detected QRS would result in a suspicious RR interval, the unreliable RR flag is set.
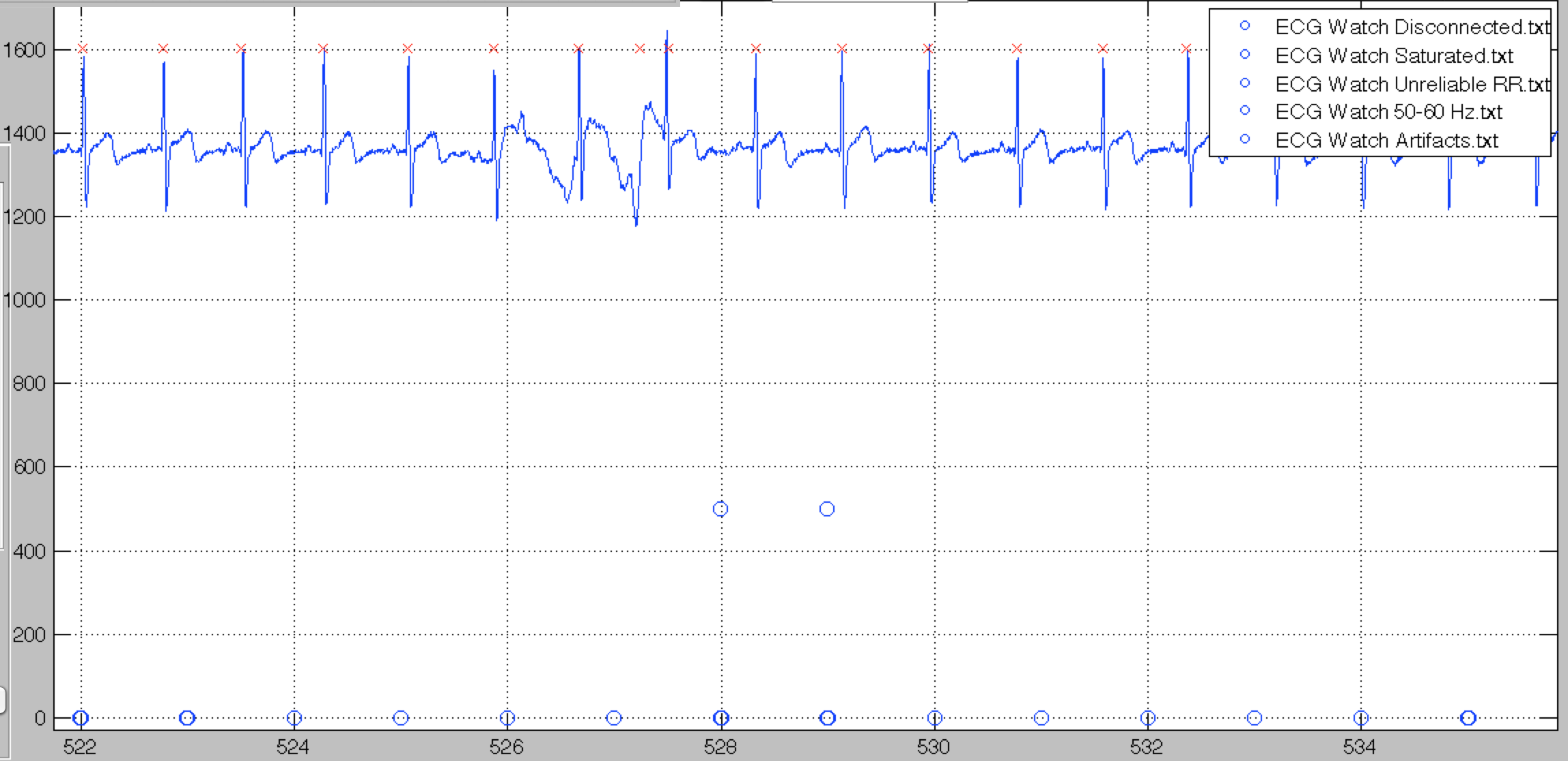 Sometimes, these can be due to some artifact like in the previous figure, but it can be caused by actual suspicious RR intervals, as in the sample shown below.
Sometimes, these can be due to some artifact like in the previous figure, but it can be caused by actual suspicious RR intervals, as in the sample shown below.
QRS
Doc: https://api.hexoskin.com/docs/resource/datatype/#QRS
RR interval
Doc: https://api.hexoskin.com/docs/resource/datatype/#RR_interval
Respiration related
From the raw respiration sensor measurements, we automatically detect Expirations and Inspirations. The tidal volume is derived from the difference between the inspiration and expiration values. The average Tidal volume, multiplied by the breathing rate, results in the Minute Ventilation.
https://api.hexoskin.com/api/data/?record=37700&datatype=37
[
{
"data": {
"37": [
[
359840228406,
571.04
],
[
359840228662,
571.04
],
[
...
]
]
},
"user": "/api/user/1511/"
}
]
Respiration Raw Data
Doc: https://api.hexoskin.com/docs/resource/#respiration/
Breathing rate
Doc: https://api.hexoskin.com/docs/resource/datatype/#breathing_rate
Expiration
Doc: https://api.hexoskin.com/docs/resource/datatype/#expiration
Inspiration
Doc: https://api.hexoskin.com/docs/resource/datatype/#inspiration
Minute ventilation
Doc: https://api.hexoskin.com/docs/resource/datatype/#minute_ventilation
Tidal volume
Doc: https://api.hexoskin.com/docs/resource/datatype/#tidal_volume
Breathing Rate Status
Doc: https://api.hexoskin.com/docs/resource/datatype/#breathing_rate_quality
Acceleration related
To compute the Activity, we filter out the low-frequency gravity component of the raw accelerometer data, then average the modulus of the three axis.
Using the raw measurements, we detect Steps automatically. The average time between steps yields the Cadence.
Finally, Sleep Positions are calculated during sleep.
Raw Accelerometer data
Doc: https://api.hexoskin.com/docs/resource/datatype/#acceleration
Activity
Doc: https://api.hexoskin.com/docs/resource/datatype/#activity
Step
Doc: https://api.hexoskin.com/docs/resource/datatype/#step
Cadence
Doc: https://api.hexoskin.com/docs/resource/datatype/#cadence
Device position
Doc: https://api.hexoskin.com/docs/resource/datatype/#device_position
Sleep-related
Sleep Position
https://api.hexoskin.com/api/data/?range=XXXXX&datatype=270
[
{
"data": {
"270": [
[
362306334580,
1
],
[
362306335092,
5
],
[
...
]
]
},
"user": "/api/user/XXXXX/"
}
]
Doc: https://api.hexoskin.com/docs/resource/datatype/#sleep_position
Sleep Phases
Doc: https://api.hexoskin.com/docs/resource/datatype/#sleep_phase
HRV
Although HRV is calculated by ECG and might be categorized under heart-rate related, it deserves its own section. Note that HRV-related metrics are only calculated for ranges of the correct activity type (12 for sleep or 106 for Rest test).
Ann
Doc: https://api.hexoskin.com/docs/resource/datatype/#ANN
HRV HF
Doc: https://api.hexoskin.com/docs/resource/datatype/#HRV_HF
HRV HF
Doc: https://api.hexoskin.com/docs/resource/datatype/#HRV_LF_normalized
HRV LF
Doc: https://api.hexoskin.com/docs/resource/datatype/#HRV_LF
NN Interval
Doc: https://api.hexoskin.com/docs/resource/datatype/#NN_interval
NN Over RR
Doc: https://api.hexoskin.com/docs/resource/datatype/#NN_over_RR
SD NN
Doc: https://api.hexoskin.com/docs/resource/datatype/#SDNN
Triangular
Doc: https://api.hexoskin.com/docs/resource/datatype/#HRV_triangular
GPS Data Resources
GPS data is acquired and available when a Range requires geolocation.
Track
https://api.hexoskin.com/api/track/?range=48328
{
"meta": {
"limit": 20,
"next": null,
"offset": 0,
"previous": null,
"total_count": 1
},
"objects": [
{
"area": null,
"distance": 13.9953509448312,
"id": 1,
"name": "",
"range": "/api/range/48328/",
"resource_uri": "/api/track/1/",
"source": "",
"user": "/api/user/805/"
}
]
}
The track object is the container for the list of GPS points that were acquired during the range execution. Because GPS is only ON when executing certain training routine, make sure that the routine you want to collect the data from has the “geo” parameter set to true.
Doc: https://api.hexoskin.com/docs/resource/track/
Track Point
https://api.hexoskin.com/api/trackpoint/?track=1
{
"meta": {
"distance": {
"/api/track/1/": 13.9953509448312
},
"limit": 20,
"next": null,
"offset": 0,
"previous": null,
"total_count": 2,
"total_tracks": 1
},
"objects": [
{
"altitude": 38,
"course": null,
"horizontal_accuracy": 4,
"id": 2,
"position": [
-73.598363,
45.5299156
],
"resource_uri": "/api/trackpoint/2/",
"speed": 5.9548716545105,
"time": "2014-08-14T05:25:17",
"track": "/api/track/1/",
"vertical_accuracy": null
}
]
}
Trackpoints are the actual GPS location points measured by the phone during the range or record.
Doc: https://api.hexoskin.com/docs/resource/trackpoint/
Structural Data Resources
https://api.hexoskin.com/api/range/61495/
{
"activityattributes": [
{
"attrtype": "user",
"id": 1,
"name": "distance",
"resource_uri": "/api/activityattribute/1/",
"unit": {
"id": 103,
"info": "",
"resource_uri": "/api/unit/103/",
"si_long": "kilometer",
"si_short": "km"
},
"user": null,
"value": null
},
{
"attrtype": "user",
"id": 2,
"name": "fatigue",
"resource_uri": "/api/activityattribute/2/",
"unit": {
"id": 2,
"info": "Qualitative scale, select between 1 and 10",
"resource_uri": "/api/unit/2/",
"si_long": "",
"si_short": ""
},
"user": null,
"value": null
},
{
"attrtype": "user",
"id": 3,
"name": "energy",
"resource_uri": "/api/activityattribute/3/",
"unit": {
"id": 400,
"info": "",
"resource_uri": "/api/unit/400/",
"si_long": "joule",
"si_short": "J"
},
"user": null,
"value": null
}
],
"created": "2014-09-08T17:42:42+00:00",
"duration": "0:00:06",
"end": 361010731008,
"id": 61495,
"last_modified": "2014-09-08T17:42:48+00:00",
"metrics": [
{
"id": 44,
"name": "heartrate_avg",
"resource_uri": "/api/metric/44/",
"title": "HR Avg",
"unit": {
"id": 700,
"resource_uri": "/api/unit/700/",
"si_long": "beats per minute",
"si_short": "bpm"
},
"value": 69.3333333333333,
"zones": [
0,
114,
133,
152,
171,
250
]
},
{
"id": 139,
"name": "energyecg_vo2_kcal",
"resource_uri": "/api/metric/139/",
"title": "energyecg vo2 kcal",
"unit": {
"id": 551,
"resource_uri": "/api/unit/551/",
"si_long": "Calorie",
"si_short": "Cal"
},
"value": 0.022502796271686363,
"zones": []
}
],
"name": "bike",
"note": "",
"parent": null,
"ranges": [],
"rank": 0,
"resource_uri": "/api/range/61495/",
"start": 361010729472,
"start_date": "2014-09-08T17:42:42+00:00",
"status": "complete",
"trainingroutine": "/api/trainingroutine/1/",
"user": "/api/user/36/"
}
https://api.hexoskin.com/api/record/37700/
{
"data": "Nh4myFMAAABIWERFVi1BVVRPNp4AAAAAJAAAAEZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGRkZGAQAFAA==",
"data_status": {},
"dev_id": "FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF",
"device": "/api/device/HXSKIN1200002070/",
"end": 359840821814,
"firmware_rev": "1.0.5",
"id": 37700,
"last_modified": "2014-07-17T20:16:50+00:00",
"n_uploaded_timelines": 0,
"npages": 8276,
"resource_uri": "/api/record/37700/",
"soft_protocole": 0,
"soft_uid": "HXDEV-AUTO",
"start": 359840226870,
"start_date": "2014-07-17T19:38:06+00:00",
"status": "complete",
"user": {
"email": "athlete@hexoskin.com",
"first_name": "Athlete",
"id": 1511,
"last_name": "Hexoskin",
"profile": "/api/profile/1460/",
"resource_uri": "/api/user/1511/",
"username": "athlete@hexoskin.com"
}
}
As mentionned in the Import/Export section, Ranges and Records can be download as more than just JSON. Refer to that section for more details.
Range
Ranges are used to instantiate training routines. They label a time period with a name and a training routine. Since training routines have an Activity Type, these activity types are indirectly related to ranges. Some training routines requires GPS. If GPS data is collected, it will be found within the range. Ranges automatically contain activity attributes and metrics as prescribed by the activitytype of the training routine to which the range relates.
In the example on the right, the activity attributes have not been set, thus their value of null. On the other hand, metrics are populated automatically.
Doc: https://api.hexoskin.com/docs/resource/range/
Record
If an Hexoskin device has an user assigned, it starts a recording automatically when connected to a garment. The record represents the time period containing Hexoskin-related data.
Doc: https://api.hexoskin.com/docs/resource/record/
Additional Info Resources
Annotation
Doc: https://api.hexoskin.com/docs/resource/annotation/
Activity Type
The activitytype attribute applies to a trainingroutine. It is an aggregator to group similar trainingroutines together. The activitytype dictates if any additionnal processing is applicable to the routine, such as :
- HRV calculations for activitytype 12 (sleep) and 106 (rest test)
- Sleep positions for activitytype 12
The activitytype also controls which metrics are returned when querying a range. These metrics are always returned by default, and adding &include_metrics=... will append other metrics to that list. The table below summarizes which activitytype returns which metrics.
- Cycling (1): 44, 139
- General sport (3): 44, 71, 139
- Resting (8): 139
- Running (10): 44, 71, 139
- Sleep (12): 139, 170, 1032, 1033, 1034, 1035, 1036, 1037, 1038, 1039
- Lifestyle (17): 44, 71, 139
For example, if a range has trainingroutine 6 (jog), it means it belongs to activitytype 10 (Running). As such, when requesting that jogging range, metrics 44, 71 and 139 will be appended automatically in the response.
Doc: https://api.hexoskin.com/docs/resource/activitytype/
Activity Attribute
Activity attributes are additionnal data for ranges that needs to be manually entered. The activity attribute object is just the template, the actual instance is the Activity Attribute Value. As the name suggests, they are activitytype-related (meaning all ranges of the same activity type have the same activity attributes).
Doc: https://api.hexoskin.com/docs/resource/activityattribute/
Activity Attribute Value
Doc: https://api.hexoskin.com/docs/resource/activityattributevalue/
Device
Doc: https://api.hexoskin.com/docs/resource/device/
Distribution
Doc: https://api.hexoskin.com/docs/resource/distribution/
Metrics
Doc: https://api.hexoskin.com/docs/resource/metric/
The list of metrics and their description can be found here : https://api.hexoskin.com/docs/resource/metric
Report
Doc: https://api.hexoskin.com/docs/resource/report/
Training Routine
https://api.hexoskin.com/api/trainingroutine/1011/
{
"activitytype": "/api/activitytype/101/",
"application_metadata": null,
"description": "The 1 mile Rockport Walk test has been designed to estimate VO2max using a sub-maximal field test. The goal is to walk 1 mile as fast as possible",
"id": 1011,
"last_used": null,
"metadata": {
"geo": true
},
"name": "1 Mile Rockport Walk Test",
"resource_uri": "/api/trainingroutine/1011/",
"steps": [
{
"activitytype": "/api/activitytype/10/",
"custom_target_high": 0,
"custom_target_low": 0,
"description": "",
"duration_type": "distance",
"duration_value": 1609,
"index": 0,
"intensity": "active",
"name": "run",
"target_type": "open",
"target_value": 0
}
],
"user": null
}
Training routines consists of a name and an activity type. They also determine whether or not the GPS should be enabled via the “geo” field, in metadata. The training routine is just the template and are instanciated as Ranges.
Doc: https://api.hexoskin.com/docs/resource/trainingroutine/
Unit
Doc: https://api.hexoskin.com/docs/resource/unit/
User Related Resources
In this section, User Resources are endpoints used to access some User-related information. Operations are endpoints that you can use to trigger server operations, such as a password reset for a user.
User resources
Account
Doc: https://api.hexoskin.com/docs/resource/account/
Bundle
Doc: https://api.hexoskin.com/docs/resource/bundle/
Bundle Permission
Doc: https://api.hexoskin.com/docs/resource/bundle_permission/
Profile
Doc: https://api.hexoskin.com/docs/resource/profile/
User
Doc: https://api.hexoskin.com/docs/resource/user/
Bundle Permission Request
Doc: https://api.hexoskin.com/docs/resource/bundle_permission_request/
User-related Operations
These operations are not actual resources, in the sense that they trigger a process on the server, but you should not expect a response from them.
Change Email
Doc: https://api.hexoskin.com/docs/resource/changeemail/
Create Related User
Doc: https://api.hexoskin.com/docs/resource/createrelateduser/
Create User
Doc: https://api.hexoskin.com/docs/resource/createuser/
Create User Request
Doc: https://api.hexoskin.com/docs/resource/createuserrequest/
Reset password
Doc: https://api.hexoskin.com/docs/resource/resetpassword/
Uploads
The Hexoskin system allows to upload data from TCX or FIT files.
Studies
Hexoskin allows to create studies in order to organize collected data, generate reports, create planning for study's subjects.
There are also preselected routines/prescription and measurement that are configured according to Hexoskin Licenses, so some metrics will be automatically linked to the study and reports. Please ask support@hexoskin.com for more info.
Users
There are 3 types of users whom can interact with the Study resource, as follow:
Study Owner
- ask support@hexoskin.com to receive this type of access
- can edit all Study parameters
- cannot see data from subjects
Study Admins
- ask support@hexoskin.com or your institution manager (the owner) to be assigned a Study
- can edit all Study parameters and planning
- can create subjects and see their data
- can see all Study parameters
Study Subjects
- are linked to study with the many-to-many relationships /api/studysubject/
- cannot log into pro.hexoskin.com
- can see Study parameters and planning
UUID
Each study has a unique identifier (called UUID). The UUID is used as prefix in subject username. In other words, each subject's username begins with the study UUID he belongs to following by an underscore and finally its own id.
Example : The subject with the ID sub001 belonging to the study test with the UUID test will have the username test_sub001
Study group
A subject belongs to a group or also commonly called cohort. A cohort is a group of people who share a defining characteristic, typically those who experienced common events, experiences or conditions in a given period.
Change subject's group
Although we expect most studies using Hexoskin garment are prospective (using the collection of new recorded data), studies can be retrospective. And thus, it is possible to assign a group to subject after its onboarding date and even after the end of the study.
Planning
{
"name": "Example 1",
"event_schedule": {
"resource_uri": "/api/activity/4/",
"start_time": "09:00",
"end_time": "10:00",
"repeat_frequency": "P1M",
"byMonthDay": [
1,
15
]
},
"description": "A description here"
}
{
"name": "Example",
"event_schedule": {
"start_time": "09:00",
"repeat_frequency": "P10D",
"resource_uri": "/api/trainingroutine/4/",
"end_time": "10:00",
"byPeriodDay": [2, 4]
}
}
{
"name": "Example",
"event_schedule": {
"resource_uri": "/api/activity/4/",
"repeat_frequency": "P7D",
"repeatCount": 2,
"start_time": "09:00",
"end_time": "10:00",
}
}
{
"name": "Example",
"event_schedule": {
"repeat_frequency": "P2D",
"resource_uri": "/api/activity/4/",
"end_date": "2021-01-12",
"start_date": "2020-12-24",
"repeatCount": 1
}
}
{
"name": "Example",
"event_schedule":
{
"start_date": "2020-12-24",
"repeat_frequency": "P1D",
"repeatCount": "10",
“start_time": "09:00",
“end_time": "10:00"
}
{
"name": "Example",
"event_schedule":
{
"start_date": "2020-12-24",
"end_date": "2021-01-24"
"repeat_frequency": "P2D",
"byPeriodDay": [2]
}
}
{
"name": "Example",
"event_schedule": {
"repeat_frequency": "P1W",
"by_week_day": [
0,
1
],
"resource_uri": "/api/activity/4/",
"repeatCount": 2
}
}
In the context of studies, it is possible to create a planning. A planning allows to schedule :
- the activities and workouts the subject must perform,
- the measurements the subject must take,
- the survey the subject must answer.
The planning is described in a JSON format. It is stored in the property planning in study.
The schema is mainly inspired by https://schema.org/Schedule although there is some differences. Instead of using camel case styles, underscore style is prefered dans un soucis de consistance. The following table shows the different properties. Some examples on the right columns are shown.
Constraints
Total Duration: The combination of repeat_count and repeat_frequency must result in a total duration that does not exceed 5 years. This constraint ensures that the planning remains within a reasonable timeframe for study purposes. For example, a repeat_frequency of "P1M" with a repeat_period of 60 (5 years) is acceptable, but a repeat_period of 61 would exceed the 5-year limit.
| Property | Type | Example | Description |
|---|---|---|---|
| repeat_frequency | ISO_8601 notation | P1M |
Defines the frequency at which Events will occur according to a schedule Schedule. The intervals between events should be defined as a Duration of time.. Based on ISO 8601 Duration (https://en.wikipedia.org/wiki/ISO_8601) |
| repeat_period | integer | 2 |
Defines the number of times a period is repeated. If 0, the period is repeated until the study end. |
| days_offset | integer | 5 |
Specifies which day from subject's start date the schedule runs. If 0, the schedule starts the same day as start date. |
| resource_uri | URI | /api/trainingroutine/1012/ |
The unique URI where the object resides. It could be activitytype, trainingroutine, survey and kpi |
| start_time | string | 09:00 |
Start time of activity, trainingroutine. In the case of a survey, it must be answered after start time. This field is optionnal. |
| end_time | string | 16:00 |
End time of activity, trainingroutine. In the case of a survey, it must be answered before end time. This field is optionnal. |
| repeat_count | integer | 2 |
Defines the number of times a recurring the event will take place |
| by_month_day | array of integer | [1, 15] |
Defines the day(s) of the month on which a recurring Event takes place. Specified as an Integer between 1-31. |
| by_week_day | array of integer | [1, 2] |
Defines the day(s) of the week on which a recurring Event takes place. Specified as an Integer between 0-6. The week starts on Monday. |
| by_period_day | array of integer | [2] |
Defines the day(s) of the period on which a recurring Event takes place. Specified as an Integer between 1-N where N is the duration of the period defined by repeat_frequency. |
| start_date | YYYY-MM-DD | 2020-12-24 |
The start date and time of the item (in ISO 8601 date format). |
| end_date | YYYY-MM-DD | 2020-12-24 |
The end date and time of the item (in ISO 8601 date format). |
Calendar
{
"meta": {
"total_count": 9
},
"objects": [
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-14",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-14",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-15",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-15",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-16",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Do 5 min Rest Test twice a day",
"done": false,
"event_schedule": {
"date": "2020-07-16",
"resource_uri": "/api/activitytype/4/"
}
},
{
"name": "Answer the survey every day",
"done": false,
"event_schedule": {
"date": "2020-07-14",
"resource_uri": "/api/survey/3/"
}
},
{
"name": "Answer the survey every day",
"done": false,
"event_schedule": {
"date": "2020-07-15",
"resource_uri": "/api/survey/3/"
}
},
{
"name": "Answer the survey every day",
"done": false,
"event_schedule": {
"date": "2020-07-16",
"resource_uri": "/api/survey/3/"
}
}
]
}
In the context of studies, a calendar informs the subject when he has to :
- perform the activities, workouts,
- answer the surveys,
- enter the manual measurements through the mobile application
The calendar is generated from the planning (described above) and the onboarding date (start_date) that may be different for each subject of a given study.
The calendar is available through /api/calendar/. The properties done informs whether the event occured. The filter end allows to get all the scheduled events before a given date.
Surveys
It is possible to create surveys in the context of studies. A survey is a set of questions that are asked to subjects in the studies. Creating a survey in a study will allow the administrator of the study to follow more closely the progress of the subjects on a particular topic of his choice. For example in the case of the COVID-19, a healthcare professionnal could have their patients fill a daily survey about the symptoms they are experiencing. The system can later on compile the answers and generate a report.
In order to use the surveys in a study, the following resources are available. Those resources allow to get surveys and post responses. Surveys should be created in the admin panel or OneView to be able to use them.
Get a survey
Doc: https://api.hexoskin.com/docs/resource/survey/
Submit a response to a survey
Doc: https://api.hexoskin.com/docs/resource/surveyanswers/
Post a response to a survey
Doc: https://api.hexoskin.com/docs/resource/csvsurveyanswers/
Doc: https://api.hexoskin.com/docs/resource/import/
Astroskin-specific resources
The Astroskin is a modified version of the Hexoskin that embeds a Pulse Oxymetry sensor, a 3-lead ECG, and a skin temperature sensor. More details available at http://www.asc-csa.gc.ca/eng/sciences/astroskin.asp
PPG
Doc: https://astro.hexoskin.com/docs/resource/datatype/#PPG/
The PPG, or PhotoPlethysmoGram, is the raw photoplethysmograph sensor measurement.
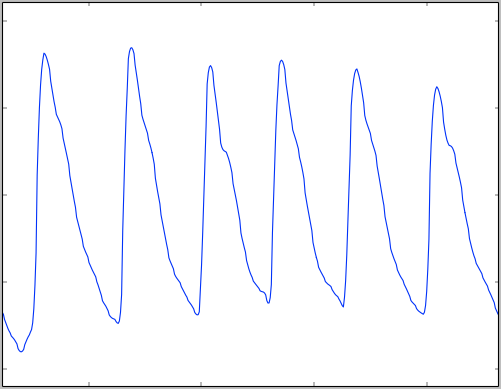
PTT
Doc: https://astro.hexoskin.com/docs/resource/datatype/#PTT/
PTT, or Pulse Transit Time, represents the transit time between the heart beat measured by the ECG electrodes and the heart beat measured from the forehead sensor. This value helps compute the Systolic pressure value.
SpO2
Doc: https://astro.hexoskin.com/docs/resource/datatype/#SPO2/
SPO2 status
Doc: https://astro.hexoskin.com/docs/resource/datatype/#SPO2_quality/
Systolic pressure
Doc: https://astro.hexoskin.com/docs/resource/datatype/#systolic_pressure/
Temperature
Doc: https://astro.hexoskin.com/docs/resource/datatype/#temperature/
Temperature status
Doc: https://astro.hexoskin.com/docs/resource/datatype/#temperature_quality/
OAuth Endpoints
OAuth Client
Doc: https://api.hexoskin.com/docs/resource/oauthclient/
OAuth2 Tokens
Doc: https://api.hexoskin.com/docs/resource/accesstoken/
OAuth2 Endpoints
- For Authorization: https://api.hexoskin.com/api/connect/oauth2/auth/
- For Token exchange: https://api.hexoskin.com/api/connect/oauth2/token/
Miscellaneous Resources
Content Type
Doc: https://api.hexoskin.com/docs/resource/contenttype/
Datafile
Doc: https://api.hexoskin.com/docs/resource/datafile/
Release Notes
4.24.0
Features/h3>
- Max number of studies associated with license
4.23.11
Fixes/h3>
- Update db_field.rel.to to db_field.remote_field.model to align with Django 2.0+ API changes
- Prevent double celery task
4.23.10
Features
- Add status INVALD for record
- Add option to hide Delete Record button on clients
4.23.8
Features
- Users requiring an access to oneview must belong to 'users' group.
4.23.7
Features
- Generated Reports: Added a "minimal" option for a more compact JSON response.
4.23.6
Bug Fixes
- Fix SpO2 quality calculation.
Release Notes
4.23.5
Bug Fixes
- HRV calculation done when record is reprocessed.
Features
- Update admin console form for report creation.
4.23.4
Bug Fixes
- Fix code to handle cases where a record has no device.
- Add buffer to tolerate clock differences.
- Fix rank filter for ranges when argument
rank=x is used.
- Only verify stats calculation when record status is complete to avoid erroneous error messages.
- Fix low motion auto-detection by renaming it to restAutodetected.
Features
- Update gRPC function to specify astro/HX.
- Add garment type and size fields to user profiles.
- Modify record end for short overlaps.
4.23.3
Bug Fixes
- Resolve intermittent decoding issues related to S3 integration.
4.23.2
Bug Fixes
- EDF export if username contains non latin characters failed
- SPO2 quality percent was wrong
4.23.1
Bug Fixes
- Fix metric tests
4.23.0
Features
- Added SPO2 quality
- Added deletion of KPI associated to a scheduled event
4.22.19
Features
- Added cloneability criteria for study
4.22.18
Bug Fixes
- Resolved issues with the planning JSON validator
- Introduced advertising on the login page (Hexoskin)
- Corrected the default display of ranges with rank greater than 0
4.22.17
Bug Fixes
- Adjusted KPI intervals for 'kid' KPIs and 'breast'
- Addressed the excessive count in Compliance KPIs
4.22.16
Bug Fixes
- Fix error 405 on schemas
- User is notified when CSFR token is about to expire
4.22.15
Bug Fixes
- Change device position calculation and documentation for astroskin device (the accelerometer is not at the same orientation as the hexoskin device)
- No score calculation when not applicable for survey
- Add MV (Minute Ventilation) and TV (Tidal Volume) to EDF files
- Latest KPI returned along with the subject profile
Features
- Compliance KPI (number of recording hours)
4.22.14
Documentation
- Metrics for 5-min rest test documented
Features
- Fix latency issue with KPI
- EDF export failed without birth date
4.22.13
Features
- Email sent to member when added to a study
- HR and BR qc in percent
4.22.12
Features
- Add sign up for OneView.
- Add HR max in documentation
Bug Fixes
- Fixed a bug for EDF file
4.22.11
Features
- Added an endpoint to add a member in a study.
- Added an endpoint to remove a member in a study.
Bug Fixes
- Fixed a bug where the API failed with status 405 on /api/studymember/schema/.
- Fixed an issue where UTC is used by default if the timezone is missing in the study payload.
- Fixed a bug where a survey was not found when making a POST request to /api/surveyanswer/.
Performance
- Improved the write_edf method for faster execution.
4.22.10
Features
- Handled error when record does not exist.
- Added a condition to delete a study.
Bug Fixes
- Fixed a planning issue where the day was out of range.
4.22.9
Features
- Added HR max and sleep metrics to the documentation
- Implemented a flow to create study admin through an email loop
- Created a login page for Astroskin
4.22.8
Fixes
- Fixed an error handling issue in the KPI endpoint
4.22.7
Improvements
- Update sanity checks on some stats and KPI
- Energy calculation updated
4.22.4
Bug fix
- Fix crash on access of data for datatype 271, 272, 273, 274, 278, 371, 372, 379
4.22.3
Features
- BRV (Breathing Rate Variability) calculation
Bug fix
- Wavfile size were not right in header.
- Delete the second record if a record has been synced twice wieth hxservice and onesync.
- Study duration input not taken into account when creating from a template
4.22.2
Bug fix
- Fix calculation of some metrics.
4.22.1
Bug fix
- BP coefficient was not returning the 2 coefficient for calculations.
4.22.0
Features
- Links to OneSync (replaces HX Service)
- Negative offset in planning
- Functionality to clone a study
4.21.4
Features
- Add a tool for administration (statistics on users)
4.21.3
Features
- Add field max_duration for study report.
- Add spitted chart for short-term report longer than 3 days so that only data of interest is diplayed.
Bug fixes
- Sign up form : password match & email validity before submiting
- Astro : record not decoded if the record is deleted
4.21.2
Bug fixes
- Fix bugs related to importation of surveys by CSV
- Fix EDF download for range (start time was not right)
- Update documentation for datatype BR for Astroskin
- Fix some issues related to processing
- Check permissions on planning, change date format (former format not accepted by mobile), change the way events are sorted (start_date and then name)
- Fix problematic default values for KPI
4.21.1
Bug fixes
- Import survey answers from CSV crashed when 2 subjects had the same UUID
4.21.0
Features
- Add kpi compliance : total_tasks_missed, total_activities_missed, total_entries_missed, total_surveys_missed
- Add devices in info.json along with raw data
Bug fixes
- Fix list of devices for subject
- Study group accepts both ID and resource uri
- Fix download EDF for range
4.20.0
Features
- Add filters to planning endpoint
- Change logic for manual entries scheduled
- Add functionality to save bp_coef
Bug fixes
- Fix surveys done were not actually flagged as done.
- Study admin must not require kpis.
- When subject start date is updated, the personal calendar must be updated.
- It was possible to associate a subject to any existing group, even to from another study.
- OneView login page crashed when already logged in as a user not study admin
- Study description is not mandatory anymore
- Remove score and scoring_method from survey response(not in FHIR spec, make mobile crash)
4.19.0
Features
- Add KPI to study subjects for compliance to the planning of the study.
Bug fixes
- Cast to bigint when calculating study duration in Hx timestamp
- Delete user was blocked
- Fix related to redis (Correct ApiKeyMiddleware._sync_key hashlib.sha1 was missing hexdigest(). So caching could not work properly for syncing.)
4.18.0
Improvements
- Upgrade Django to 3.2, and Python to 3.9.
Features
- Subject plannings stored in the database (not calculated on the fly anymore) allows more flexibility.
- Increase sanity limits on bmi.
- Allow to filter planning by user.
- Allow to update a event schedule when uploading survey answers.
Features
- Correct BP calculation. Now on bp adjusted. Filter out BP where bp_status whatchdog are on.
- First try of a sync of an astroskin timeline was returning an error 400 even if the data was processed correctly.
- Allow to not standard timezone such as Japan (not from common tz).
4.17.1
Bug fixes
- Owner field missing in study creation form
- More validation check on template_id field in study creation from template
4.17.0
Features
- Add systolic pressure quality signal available for download
- Add the possibility to create a study from a template
4.16.2
Bug fixes
- Survey : sort rows of CSV by survey, user, study, authored
- Fix bugs related to survey scoring
- Survey : support for multiple choices in survey answers
- Sync : the first try of a sync of an astroskin timeline was returning an error 400 even if the data was processed correctly
- Subject planning : only take into account ranges with rank=0
- Report : time and date format on X axis depends on the period duration (short-term vs long-term reports)
4.16.1
- New configuration setting for report microservice
4.16.0
Features
- Add score to surveys
- Ability to create report templates from admin console (templates are now stored in the database)
4.15.0
Features
- Support for groups/sub-questions in surveys
- A GET on csvsurveyanswers return surveys answers as a CSV file.
- Make it easier to create and change surveys in the admin console
Bug fixes
- Access to survey answers : only subject and study admins may access answers
- 403 errors : some endpoints did not return the right error code.
Documentation
- Update SPO2 status documentation
4.14.0
Features
- Survey : allow to sort questions and question choices
4.13.1
Bug fixes
- Calendar : 'done' flags wrongly equal to true when just one task was done for tasks scheduled over a period of several days.
Other
- /api/datafile/ is now deprecated
- Remove filters on endpoint /data/
- Update documentation on hr_status
4.13
Features
- Add timezone, start and user_id filter to the endpoint /api/calendar/
- Generated reports are now accessible to all study admins
Bug fixes
- Zones, distribution and kpi are returned relative to the start time specified in the api call rather
than relative to the actual time
- Calendar was crashing if no subject start_date
- Duplicate scheduled tasks were not handled and the completed flag 'done' turned out to be true
by mistake in some cases.
4.12
Features
- Ability to create study template from existing study and to create study from study template.
- Ability to filter and search record by device in the admin console.
- Fix bug with device numbering for Astroskin.
- Fix bug with fetching undersample data.
- Allow to sync astroskin record as hexoskin record.
Bug fixes
- On astroskin version, datatype 1004 was not saved. Update tests to have astroskin data return datatype 1004 And astroskin test was perform with a device model hexoskin smart.
- Fix documentation for astroskin version (update frequency, add missing datatype) Set bp_coefficient use kpi to visible.
- Reprocessing returned error if range was deleted before celery task was executed.
- Processing crashed when record had no device associated.
4.11
Features
- HRV daily and summary reports
- Bar chat for generated reports
4.10.15
Bug fixes
- Fix bug with calendar. Error occured when planning was empty.
- Correct documentation relating to records
- Fix bug with device numbering for Astroskin
- Fix bug with fetching undersample data
Features
- Filter surveys by study
4.10.14
Bug fixes
- Correct name for adjusted metrics.
4.10.13
Documentation
- Update record's documentation. Clarify mandatory fields and optional fields on a post/patch
Bug fixes
- User should be active when creating the associated subject
4.10.12
Bug fixes
- Update algo version (2.2.0) for all records
4.10.11
Bug fixes
- Data sharing : fix cache problem.
- Announcements : fix a permission problem.
- Device and record resources : clear cache when object saved.
- Recalculate "adjusted" metrics following the discovery of a processing error. The affected metrics are: minute_ventilation_adjusted_avg, minute_ventilation_adjusted_min, minute_ventilation_adjusted_max, tidal_volume_adjusted_avg, tidal_volume_adjusted_min, tidal_volume_adjusted_max.
4.10.10
Bug fixes
- Survey : return a 400 Bad Request error if the payload is not well formatted.
- Creation of coach-athlete relationship : flow improved. An 500 error occurred in some cases.
- Filters start/end and lte/gte on profile fixed. They were previously deactivated.
- Statistics are reprocessed if the calculation failed a first time.
Improvements
- Planning : add days_offset and repeat_period fields for more flexibility
- Documentation : add more details about study, PPG and PTT
- Survey (/api/surveyanswers/): add filters on results
- Study : (/api/study/): information about the study's owner are provided in the resource study
- QRS detected using ECG from the 3 leads when they are available.
4.10.9
Bug fixes
- Remove records tagged as deleted in response
- Receive study id and survey id as parameters on the api call and replace the subject id in the csv by the subject uuid.
Improvements
- Add studySubject "short_metric" query for faster api call
4.10.8
Bug fixes
- Upgrade django oauth library to fix concurrency error.
- Bugfix kpi bmi error on delete of weight /height
- Replace generic ‘Oops error’ by the actual error in sign up page.
- Add a coach relationship between subject and study admin (needed for HxServices)
Features
- Add training routine in planning and calendar
- Allow to change group of a subject in csvstudysubject
- Add time support in surveys
Improvements
- Remove metrics info on range/record call for faster api call
4.10.7
Bug fixes
- /api/createrelateduser/ crashed in some cases
4.10.6
Bug fixes
- sleep_efficiency, sleep_latency and sleep_total_time were not calculated for sleep
4.10.5
Bug fixes
- Fix a bug affecting the KPI.
4.10.4
Features
- Calendar resource for study's subjects
- Allow to choose unit system when importing a csv file
- Add last_modified on study_subject's kpi
Improvements
- Profile are now faster to load
Bug fixes
- Correct missing statistics for sleep
- Update db_field.rel.to to db_field.remote_field.model to align with Django 2.0+ API changes
- Prevent double celery task
4.23.10
Features
- Add status INVALD for record
- Add option to hide Delete Record button on clients
4.23.8
Features
- Users requiring an access to oneview must belong to 'users' group.
4.23.7
Features
- Generated Reports: Added a "minimal" option for a more compact JSON response.
4.23.6
Bug Fixes
- Fix SpO2 quality calculation.
Release Notes
4.23.5
Bug Fixes
- HRV calculation done when record is reprocessed.
Features
- Update admin console form for report creation.
4.23.4
Bug Fixes
- Fix code to handle cases where a record has no device.
- Add buffer to tolerate clock differences.
- Fix rank filter for ranges when argument
rank=xis used. - Only verify stats calculation when record status is complete to avoid erroneous error messages.
- Fix low motion auto-detection by renaming it to restAutodetected.
Features
- Update gRPC function to specify astro/HX.
- Add garment type and size fields to user profiles.
- Modify record end for short overlaps.
4.23.3
Bug Fixes
- Resolve intermittent decoding issues related to S3 integration.
4.23.2
Bug Fixes
- EDF export if username contains non latin characters failed
- SPO2 quality percent was wrong
4.23.1
Bug Fixes
- Fix metric tests
4.23.0
Features
- Added SPO2 quality
- Added deletion of KPI associated to a scheduled event
4.22.19
Features
- Added cloneability criteria for study
4.22.18
Bug Fixes
- Resolved issues with the planning JSON validator
- Introduced advertising on the login page (Hexoskin)
- Corrected the default display of ranges with rank greater than 0
4.22.17
Bug Fixes
- Adjusted KPI intervals for 'kid' KPIs and 'breast'
- Addressed the excessive count in Compliance KPIs
4.22.16
Bug Fixes
- Fix error 405 on schemas
- User is notified when CSFR token is about to expire
4.22.15
Bug Fixes
- Change device position calculation and documentation for astroskin device (the accelerometer is not at the same orientation as the hexoskin device)
- No score calculation when not applicable for survey
- Add MV (Minute Ventilation) and TV (Tidal Volume) to EDF files
- Latest KPI returned along with the subject profile
Features
- Compliance KPI (number of recording hours)
4.22.14
Documentation
- Metrics for 5-min rest test documented
Features
- Fix latency issue with KPI
- EDF export failed without birth date
4.22.13
Features
- Email sent to member when added to a study
- HR and BR qc in percent
4.22.12
Features
- Add sign up for OneView.
- Add HR max in documentation
Bug Fixes
- Fixed a bug for EDF file
4.22.11
Features
- Added an endpoint to add a member in a study.
- Added an endpoint to remove a member in a study.
Bug Fixes
- Fixed a bug where the API failed with status 405 on /api/studymember/schema/.
- Fixed an issue where UTC is used by default if the timezone is missing in the study payload.
- Fixed a bug where a survey was not found when making a POST request to /api/surveyanswer/.
Performance
- Improved the write_edf method for faster execution.
4.22.10
Features
- Handled error when record does not exist.
- Added a condition to delete a study.
Bug Fixes
- Fixed a planning issue where the day was out of range.
4.22.9
Features
- Added HR max and sleep metrics to the documentation
- Implemented a flow to create study admin through an email loop
- Created a login page for Astroskin
4.22.8
Fixes
- Fixed an error handling issue in the KPI endpoint
4.22.7
Improvements
- Update sanity checks on some stats and KPI
- Energy calculation updated
4.22.4
Bug fix
- Fix crash on access of data for datatype 271, 272, 273, 274, 278, 371, 372, 379
4.22.3
Features
- BRV (Breathing Rate Variability) calculation
Bug fix
- Wavfile size were not right in header.
- Delete the second record if a record has been synced twice wieth hxservice and onesync.
- Study duration input not taken into account when creating from a template
4.22.2
Bug fix
- Fix calculation of some metrics.
4.22.1
Bug fix
- BP coefficient was not returning the 2 coefficient for calculations.
4.22.0
Features
- Links to OneSync (replaces HX Service)
- Negative offset in planning
- Functionality to clone a study
4.21.4
Features
- Add a tool for administration (statistics on users)
4.21.3
Features
- Add field max_duration for study report.
- Add spitted chart for short-term report longer than 3 days so that only data of interest is diplayed.
Bug fixes
- Sign up form : password match & email validity before submiting
- Astro : record not decoded if the record is deleted
4.21.2
Bug fixes
- Fix bugs related to importation of surveys by CSV
- Fix EDF download for range (start time was not right)
- Update documentation for datatype BR for Astroskin
- Fix some issues related to processing
- Check permissions on planning, change date format (former format not accepted by mobile), change the way events are sorted (start_date and then name)
- Fix problematic default values for KPI
4.21.1
Bug fixes
- Import survey answers from CSV crashed when 2 subjects had the same UUID
4.21.0
Features
- Add kpi compliance : total_tasks_missed, total_activities_missed, total_entries_missed, total_surveys_missed
- Add devices in info.json along with raw data
Bug fixes
- Fix list of devices for subject
- Study group accepts both ID and resource uri
- Fix download EDF for range
4.20.0
Features
- Add filters to planning endpoint
- Change logic for manual entries scheduled
- Add functionality to save bp_coef
Bug fixes
- Fix surveys done were not actually flagged as done.
- Study admin must not require kpis.
- When subject start date is updated, the personal calendar must be updated.
- It was possible to associate a subject to any existing group, even to from another study.
- OneView login page crashed when already logged in as a user not study admin
- Study description is not mandatory anymore
- Remove score and scoring_method from survey response(not in FHIR spec, make mobile crash)
4.19.0
Features
- Add KPI to study subjects for compliance to the planning of the study.
Bug fixes
- Cast to bigint when calculating study duration in Hx timestamp
- Delete user was blocked
- Fix related to redis (Correct ApiKeyMiddleware._sync_key hashlib.sha1 was missing hexdigest(). So caching could not work properly for syncing.)
4.18.0
Improvements
- Upgrade Django to 3.2, and Python to 3.9.
Features
- Subject plannings stored in the database (not calculated on the fly anymore) allows more flexibility.
- Increase sanity limits on bmi.
- Allow to filter planning by user.
- Allow to update a event schedule when uploading survey answers.
Features
- Correct BP calculation. Now on bp adjusted. Filter out BP where bp_status whatchdog are on.
- First try of a sync of an astroskin timeline was returning an error 400 even if the data was processed correctly.
- Allow to not standard timezone such as Japan (not from common tz).
- Owner field missing in study creation form
- More validation check on template_id field in study creation from template
- Add systolic pressure quality signal available for download
- Add the possibility to create a study from a template
- Survey : sort rows of CSV by survey, user, study, authored
- Fix bugs related to survey scoring
- Survey : support for multiple choices in survey answers
- Sync : the first try of a sync of an astroskin timeline was returning an error 400 even if the data was processed correctly
- Subject planning : only take into account ranges with rank=0
- Report : time and date format on X axis depends on the period duration (short-term vs long-term reports)
- New configuration setting for report microservice
- Add score to surveys
- Ability to create report templates from admin console (templates are now stored in the database)
- Support for groups/sub-questions in surveys
- A GET on csvsurveyanswers return surveys answers as a CSV file.
- Make it easier to create and change surveys in the admin console
- Access to survey answers : only subject and study admins may access answers
- 403 errors : some endpoints did not return the right error code.
- Update SPO2 status documentation
- Survey : allow to sort questions and question choices
- Calendar : 'done' flags wrongly equal to true when just one task was done for tasks scheduled over a period of several days.
- /api/datafile/ is now deprecated
- Remove filters on endpoint /data/
- Update documentation on hr_status
- Add timezone, start and user_id filter to the endpoint /api/calendar/
- Generated reports are now accessible to all study admins
- Zones, distribution and kpi are returned relative to the start time specified in the api call rather than relative to the actual time
- Calendar was crashing if no subject start_date
- Duplicate scheduled tasks were not handled and the completed flag 'done' turned out to be true by mistake in some cases.
- Ability to create study template from existing study and to create study from study template.
- Ability to filter and search record by device in the admin console.
- Fix bug with device numbering for Astroskin.
- Fix bug with fetching undersample data.
- Allow to sync astroskin record as hexoskin record.
- On astroskin version, datatype 1004 was not saved. Update tests to have astroskin data return datatype 1004 And astroskin test was perform with a device model hexoskin smart.
- Fix documentation for astroskin version (update frequency, add missing datatype) Set bp_coefficient use kpi to visible.
- Reprocessing returned error if range was deleted before celery task was executed.
- Processing crashed when record had no device associated.
- HRV daily and summary reports
- Bar chat for generated reports
- Fix bug with calendar. Error occured when planning was empty.
- Correct documentation relating to records
- Fix bug with device numbering for Astroskin
- Fix bug with fetching undersample data
- Filter surveys by study
- Correct name for adjusted metrics.
- Update record's documentation. Clarify mandatory fields and optional fields on a post/patch
- User should be active when creating the associated subject
- Update algo version (2.2.0) for all records
- Data sharing : fix cache problem.
- Announcements : fix a permission problem.
- Device and record resources : clear cache when object saved.
- Recalculate "adjusted" metrics following the discovery of a processing error. The affected metrics are: minute_ventilation_adjusted_avg, minute_ventilation_adjusted_min, minute_ventilation_adjusted_max, tidal_volume_adjusted_avg, tidal_volume_adjusted_min, tidal_volume_adjusted_max.
- Survey : return a 400 Bad Request error if the payload is not well formatted.
- Creation of coach-athlete relationship : flow improved. An 500 error occurred in some cases.
- Filters start/end and lte/gte on profile fixed. They were previously deactivated.
- Statistics are reprocessed if the calculation failed a first time.
- Planning : add days_offset and repeat_period fields for more flexibility
- Documentation : add more details about study, PPG and PTT
- Survey (/api/surveyanswers/): add filters on results
- Study : (/api/study/): information about the study's owner are provided in the resource study
- QRS detected using ECG from the 3 leads when they are available.
- Remove records tagged as deleted in response
- Receive study id and survey id as parameters on the api call and replace the subject id in the csv by the subject uuid.
- Add studySubject "short_metric" query for faster api call
- Upgrade django oauth library to fix concurrency error.
- Bugfix kpi bmi error on delete of weight /height
- Replace generic ‘Oops error’ by the actual error in sign up page.
- Add a coach relationship between subject and study admin (needed for HxServices)
- Add training routine in planning and calendar
- Allow to change group of a subject in csvstudysubject
- Add time support in surveys
- Remove metrics info on range/record call for faster api call
- /api/createrelateduser/ crashed in some cases
- sleep_efficiency, sleep_latency and sleep_total_time were not calculated for sleep
- Fix a bug affecting the KPI.
- Calendar resource for study's subjects
- Allow to choose unit system when importing a csv file
- Add last_modified on study_subject's kpi
- Profile are now faster to load
- Correct missing statistics for sleep